


MacroChronics WEEK AHEAD 25 (27/8/2023)
Especial Nvidia: Tudo o que você precisa sobre a ação do ano!

A Nvidia (NASDAQ:NVDA) é líder em IA e computação de alto desempenho, oferece produtos e soluções inovadoras para vários setores e aplicativos, incluindo hardware como GPUs e software. A visão da Nvidia é alimentar a era da Cryptos, game, IA e do metaverso, onde a colaboração virtual, a simulação e a criatividade são perfeitas e imersivas. A empresa é líder na fabricação de GPUs, que é usada para treinar e acessar rapidamente grandes modelos de IA de linguagem e imagem, criar e usar tecnologias metaverso e VR, criptomoedas de minas e consoles de jogos.
A arquitetura Hopper da Nvidia é a próxima geração de tecnologia de GPU que permitirá desempenho, escalabilidade e segurança sem precedentes para todos os data centers. A arquitetura Hopper consiste em dois tipos de GPUs: a GPU H-100 Tensor Core e a GPU Grasshopper General Purpose.
A GPU H-100 é a GPU focada em IA mais poderosa que a empresa já fez, superando seu chip high-end anterior, o A100. A GPU H-100 inclui 80 bilhões de transistores e um mecanismo de transformador especial para acelerar as tarefas de aprendizado de máquina. Ele também suporta Nvidia NVLink, que liga GPUs para multiplicar o desempenho. A GPU H-100 foi projetada para lidar com o grande número de aplicativos e redes neurais profundas (DNNs) que funcionam simultaneamente em veículos autônomos, robótica, saúde e ciências da vida.

Salto de desempenho da GPU H-100 em relação ao chip A-100 da geração anterior A GPU Grasshopper é a GPU de uso geral mais versátil que a empresa já fez, superando seu chip principal anterior, o RTX 3090. A GPU Grasshopper inclui 60 bilhões de transistores e um novo mecanismo de rastreamento de raios para melhorar a qualidade gráfica e o realismo. Ele também suporta Nvidia Multi-Instance GPU, MIG, que particiona uma única GPU em várias instâncias para diferentes cargas de trabalho. A GPU Grasshopper foi projetada para alimentar os jogos, simulações e aplicativos criativos mais exigentes do metaverso.

A Nvidia está colaborando com as principais instituições de pesquisa e empresas para alavancar redes neurais de transformadores para descoberta de medicamentos e análise de dados clínicos. Arquiteturas de redes neurais baseadas em transformadores como o GPT-4 “permitem que os pesquisadores aproveitem conjuntos de dados massivos usando métodos de treinamento auto-supervisionados, evitando a necessidade de exemplos rotulados manualmente durante o pré-treinamento”. Esses modelos estão encontrando aplicações em domínios e modalidades de pesquisa.
A Nvidia e a farmacêutica AstraZeneca (AZN) fizeram uma parceria para desenvolver um modelo de IA generativa baseado em transformador para estruturas químicas usadas na descoberta de medicamentos que estará entre os primeiros projetos a serem executados no Cambridge-1, que em breve estará online como o maior supercomputador do Reino Unido. O modelo será de código aberto, disponível para pesquisadores e desenvolvedores no catálogo de software NVIDIA NGC e implantável na plataforma NVIDIA para descoberta computacional de medicamentos.
Universidade da Flórida, “A UF Health está aproveitando a estrutura Megatron de última geração da Nvidia e o modelo pré-treinado BioMegatron para desenvolver o GatorTron, o maior modelo de linguagem clínica até o momento.” O GatorTron tem como objetivo extrair insights de enormes volumes de dados clínicos com velocidade e clareza sem precedentes, permitindo uma pesquisa mais rápida e a tomada de decisões médicas.
Absolutamente, o conceito de "moat" (fosso competitivo) é fundamental na avaliação de investimentos em empresas com foco em crescimento. O moat refere-se à vantagem competitiva durável que uma empresa possui sobre seus concorrentes, permitindo que ela mantenha sua posição dominante no mercado e proteja seus lucros a longo prazo. Existem diferentes tipos de moats, como:
Moat de Custo: Quando uma empresa é capaz de produzir produtos ou serviços a um custo muito menor do que seus concorrentes, ela pode estabelecer uma vantagem de preço.
Moat de Rede: Empresas com redes de usuários ou clientes estabelecidas têm uma vantagem significativa. Quanto mais pessoas usam um serviço, mais valioso ele se torna, criando um ciclo de feedback positivo.
Moat de Intangíveis: Propriedade intelectual, marcas fortes e patentes podem proteger uma empresa da competição direta.
Moat de Interruptibilidade: Empresas com produtos ou serviços que são difíceis de substituir ou interromper têm um moat de interruptibilidade. Isso pode ser devido a altos custos de mudança para os clientes ou à complexidade técnica.
Moat de Efeito de Escala: À medida que uma empresa cresce, ela pode se beneficiar de economias de escala, tornando-se mais eficiente e reduzindo os custos de produção.
Moat de Troca de Hábito: Quando os clientes estão acostumados com um produto ou serviço e têm dificuldade em mudar para alternativas, a empresa tem um moat de troca de hábito.
Início da IA, a plataforma de computação CUDA da Nvidia, seu maior MOAT
A CUDA foi provavelmente o principal fator que permitiu que a Nvidia construísse uma posição tão dominante no treinamento de IA. Ian Buck foi o pai do conceito. Enquanto estudava em Stanford, ele teve a visão de executar linguagens de programação de uso geral em GPUs. A Nvidia gostou dessa ideia e financiou seu doutorado, do qual surgiu uma nova linguagem de programação chamada Brook. Antes disso, as GPUs tinham que ser programadas com APIs de programação gráfica especializadas, como DirectX ou OpenGL, um processo bastante complicado. O que também reduziu drasticamente o pool de talentos disponíveis para desbloquear o tremendo poder de computação das GPUs, já que a maioria dos desenvolvedores seria habilidosa em programação de propósito geral, mas muito menos em programação gráfica.
Após essa engenharia inicial de GPU em Stanford, Buck foi algumas milhas a sudeste para transformar isso em um produto comercial na Nvidia. Dois anos depois, em novembro de 2006, a primeira plataforma CUDA foi enviada com o Geforce 8800. A escolha foi feita para se afastar de Brook e permitir que as GPUs da Nvidia processem código C/C++. A principal razão foi que muitos desenvolvedores realmente não queriam aprender uma nova linguagem e C/C++ era a principal linguagem de programação na indústria de jogos, bem como para outros aplicativos de alto desempenho. Isso permitiria que as empresas aproveitassem o amplo e diversificado pool de talentos de programadores de jogos para usar este novo brinquedo para enormes cargas de trabalho computacionais.
Um artigo da Anandtech escrito na época explica esse novo recurso CUDA:
“A principal coisa a tirar disso é que a Nvidia terá um compilador C capaz de gerar código direcionado à sua arquitetura. Não estamos falando de algum código OpenGL manipulado para usar hardware gráfico para matemática. Este será o código C escrito como um desenvolvedor escreveria C. Um programador será capaz de tratar o Geforce como um mecanismo de processamento de dados extremamente paralelo. Os aplicativos que exigem poder de computação massivamente paralelo verão uma enorme velocidade ao serem executados no Geforce em comparação com a CPU. Isso inclui análise financeira, manipulação de matrizes, processamento de física e todos os tipos de cálculos científicos.”
Estamos falando de 2006 !!! ( 17 anos atras )
Os documentos da Nvidia explicam as diferenças entre uma CPU e uma GPU:
“Enquanto a CPU é projetada para se destacar na execução de uma sequência de operações, chamada de thread, o mais rápido possível e pode executar algumas dezenas desses threads em paralelo, a GPU foi projetada para se destacar na execução de milhares deles em paralelo. A GPU é especializada para cálculos altamente paralelos e, portanto, projetada de tal forma que mais transistores sejam dedicados ao processamento de dados, em vez de cache de dados e controle de fluxo. O esquema mostra um exemplo de distribuição de recursos de chip para uma CPU versus uma GPU.”
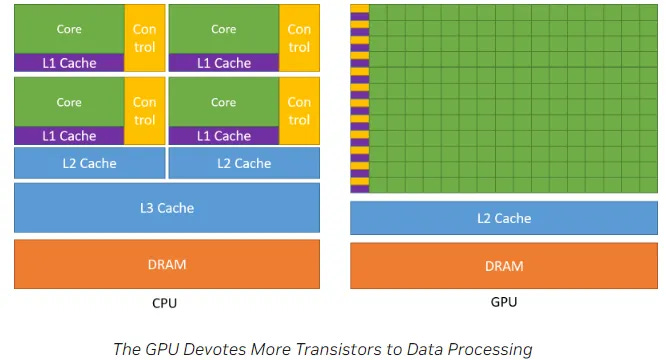
Inicialmente, a CUDA encontrou seu uso em computação de alto desempenho, simulação e outros empreendimentos científicos. No entanto, a grande oportunidade começou a surgir em 2012, quando pesquisadores no Canadá conseguiram treinar uma rede neural de 60 milhões de parâmetros em uma GPU que poderia classificar milhões de imagens de alta resolução. Isso foi imediatamente útil, pois permitiu que as grandes empresas de internet entendessem o conteúdo que seus usuários estavam postando. Isso realmente catapultou o campo do aprendizado de máquina com um avanço após o outro até hoje.
Uma ilustração abaixo de uma rede neural onde cada neurônio em uma camada está conectado a cada neurônio na camada subsequente por meio de uma ponderação, que determina a largura da conexão. Os pesos ideais são encontrados por cálculo, ou seja, derivação e grandes quantidades de interação. Todos os tipos de cálculos para os quais as GPUs são ideais.
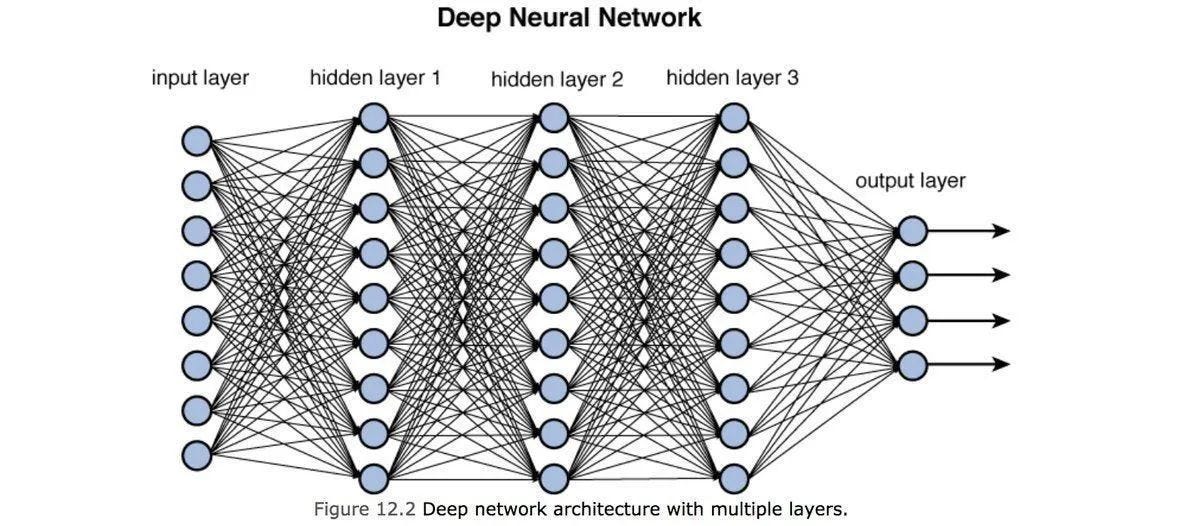
Uma inovação-chave recente neste campo são os transformadores, desenvolvidos em 2018 no Google e popularizados pela OpenAI no final de 2022 com o ChatGPT.
abre aspas para Ian Buck:
“Antes disso, a maioria dos aplicativos era baseada em convolução. Eles estavam basicamente olhando para bairros de informações e construindo uma compreensão a partir de dados localizados. Isso faz sentido no reconhecimento de imagem para reconhecer o rosto. O Transformers foi baseado na ideia de atenção, descobrindo relacionamentos distantes e incorporando-os em uma rede neural. Não há banco de dados lá atrás. É uma grande rede neural, mas a razão pela qual o ChatGPT é tão grande, o modelo de 530 bilhões de parâmetros que treinamos em nosso supercomputador, tem que capturar a humanologia em algum nível. Acho que estamos à beira do início da IA gerativa. Há um trilhão de modelos de parâmetros atrás de portas fechadas. Eles estão começando a ficar um pouco mais secretos e não lançando esses modelos enormes.”
Então podemos afirmar que o CUDA é hoje um dos principais MOAT´s da NVIDIA.
Pytorch - Rei da codificação em AI
Pytorch se tornou a estrutura dominante para escrever modelos de IA. Esta biblioteca basicamente fornece objetos e funções Python para que você possa escrever todo o seu código de IA necessário em Python, muito mais fácil de usar. Por baixo, o Python está sendo executado em linguagem C, menos fácil de usar, que é extremamente rápido e que se comunica com a plataforma de computação da GPU, CUDA.
Historicamente, a estrutura concorrente TensorFlow costumava ser dominante, mas agora o mundo acadêmico e profissional mudou em grande parte para Pytorch. A razão é que o Pytorch é muito mais granular, você pode escrever seu código de IA exatamente da maneira que deseja que ele seja executado.
Hugging Face é uma plataforma online para desenvolvedores compartilharem modelos de IA e ilustram o domínio de Pytorch:
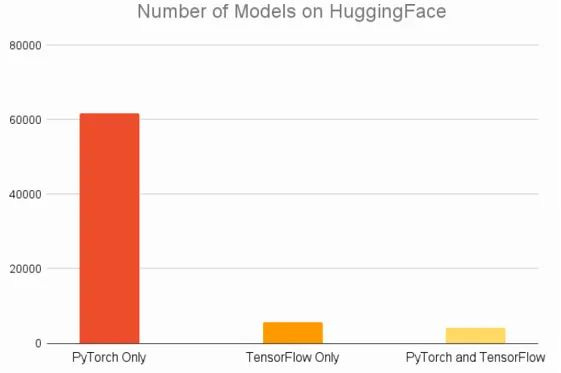
Da mesma forma, os acadêmicos mudaram em grande parte para Pytorch (gráfico da AssemblyAI):
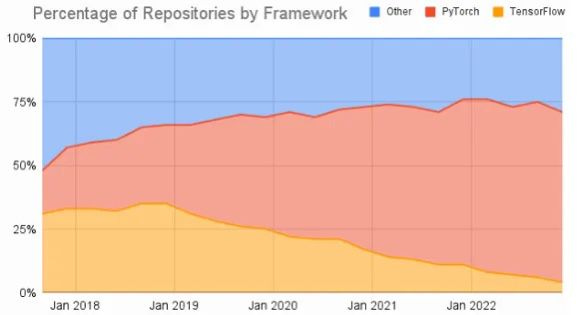
Agora, como a CUDA era historicamente a única plataforma de computação que permitia que uma linguagem de programação de propósito geral fosse executada em uma GPU, e como as GPUs da Nvidia estavam amplamente disponíveis devido à sua posição dominante no mercado de jogos, cada uma dessas bibliotecas de IA Python está executando em cima da CUDA. Eles também fornecem suporte para CPUs, mas todo o treinamento de IA está acontecendo em GPUs de qualquer maneira. Você pode treinar um projeto de hobby doméstico em uma CPU, por exemplo.
Então isso significava que você não poderia comprar uma GPU AMD e executar seu código Pytorch ou TensorFlow nela. Considerando que todas as GPUs Nvidia tinham suporte interno para CUDA e, portanto, permitiam que elas fossem facilmente adotadas para treinamento de IA. Esse é um grande problema para a AMD.
As coisas estão mudando gradualmente. A AMD também vem construindo sua plataforma de computação GPU, chamada ROCm (‘rock-em’). E a captura de tela abaixo está destacando como sua plataforma agora é suportada pelo Pytorch para sistemas operacionais Linux. O suporte nos sistemas Windows e Mac ainda está em andamento. Mas como o Linux é o principal sistema operacional no mercado de servidores, e é aí que todo o treinamento de IA está acontecendo; é realmente o principal mercado final de qualquer maneira.
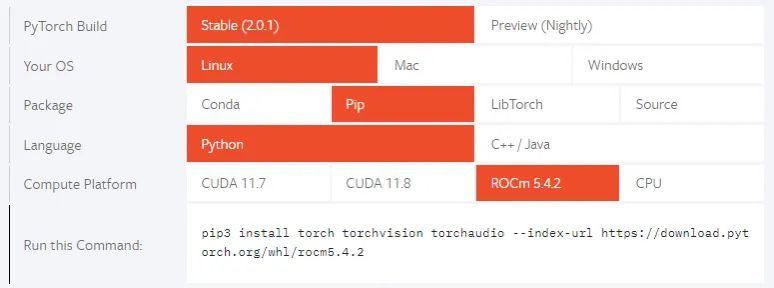
No mês passado, o fundador da Pytorch se apresentou no evento do datacenter da AMD, destacando os investimentos que ambos os lados estão fazendo para aumentar a colaboração. No mesmo evento, o CEO da Hugging Face comentou que “é realmente importante que o hardware não se torne o gargalo ou gatekeeper da IA quando ele se desenvolver”. A AMD, por sua vez, vem consolidando todas as suas atividades de IA sob Victor Peng, o que deve colocá-los em uma posição melhor para construir ainda mais seu ecossistema de software com esses parceiros cruciais.
Da mesma forma, o TensorFlow também está construindo suporte para o ROCm. Esta biblioteca foi originalmente desenvolvida no Google, mas agora eles estão se movendo em uma segunda direção com o desenvolvimento do Jax, uma biblioteca de IA mais funcional. Olhando para o site da Jax, só há suporte para CUDA em GPUs disponíveis atualmente, embora a estrutura também possa ser executado nos aceleradores TPU do Google na nuvem. O TPU é um chip de IA personalizado projetado pelo Google para treinamento e inferência, ou seja, fazendo uso de um modelo pré-treinado. Do site da Jax:

A conclusão geral aqui é que gradualmente o ecossistema de IA também está construindo suporte para ROCm, o que permitiria que as GPUs da AMD fossem facilmente utilizadas para treinamento de IA. Os desenvolvedores poderiam alugar servidores na nuvem para treinamento de IA e não saber quais GPUs estão fazendo o treinamento real por baixo. Semelhante a como você pode não saber se o seu PC está rodando em uma CPU Intel ou uma da AMD. Essa fragmentação de hardware já está acontecendo no mundo da CPU em nuvem também.
O mundo do CPU do datacenter está se fragmentando, os riscos que a NVIDIA pode enfrentar daqui para frente
Embora seja amplamente conhecido como a Intel tem sangrado com a participação da AMD nos últimos cinco anos no mercado de datacenters, os recém-chegados também estão procurando obter uma parte da ação, como a Ampere, que vem projetando CPUs de alto núcleo otimizadas para cargas de trabalho na nuvem.
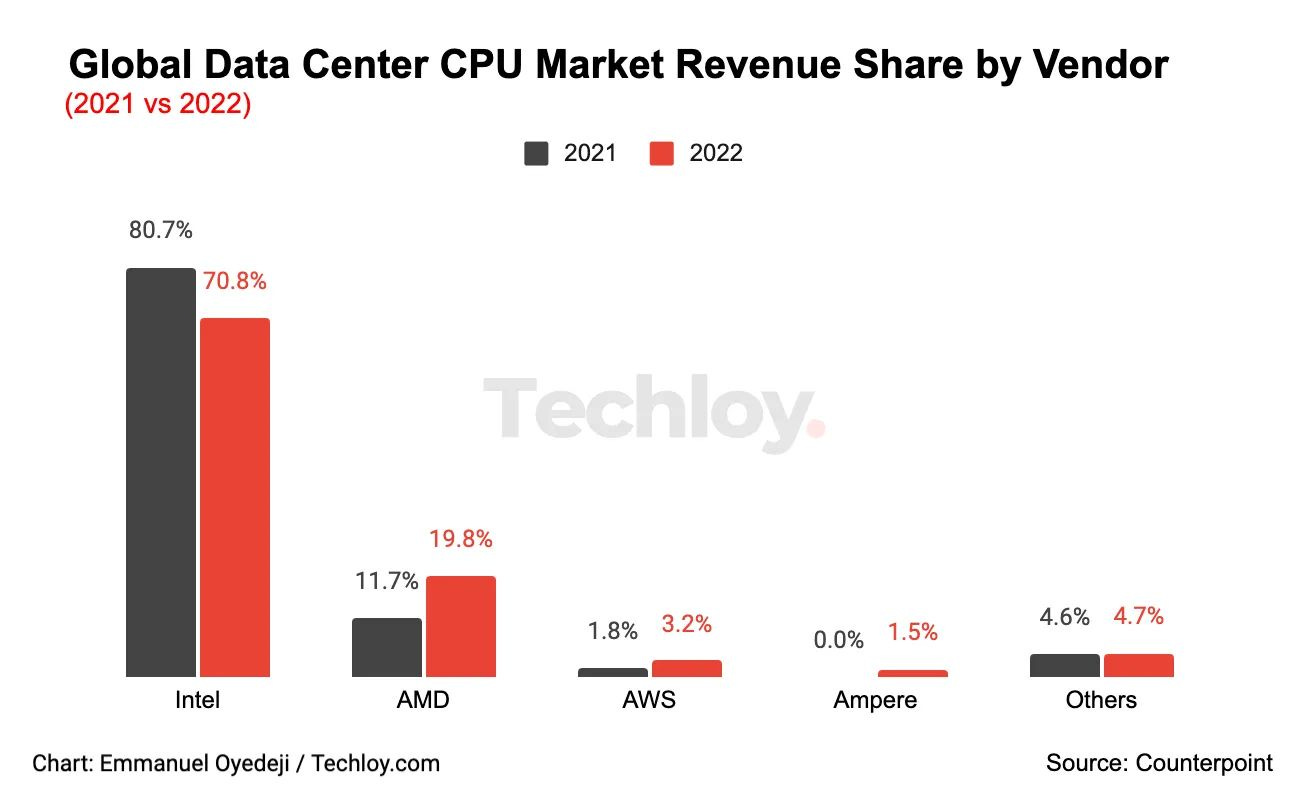
A AWS da Amazon está em uma posição ainda melhor para compartilhar ainda mais, pois eles podem aproveitar sua posição extremamente forte na nuvem (gráfico da Statista):
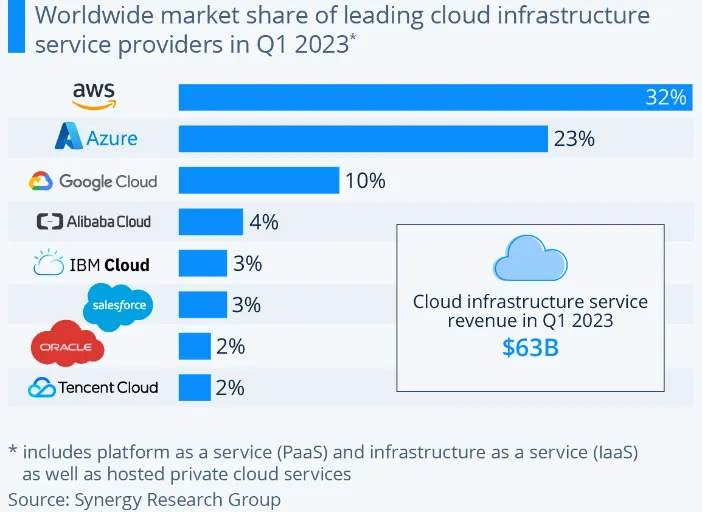
O surgimento do chip Graviton da AWS, especialmente o Graviton 2, trouxe avanços significativos em termos de desempenho e variedade de instâncias, colocando-o em uma posição competitiva em relação às ofertas da Intel. O que se destaca é que esses chips são baseados na arquitetura ARM, o que permite uma execução mais suave de linguagens de programação principais, como Java e Python. Embora recompilação seja necessária para linguagens como C++, o processo é relativamente fácil.
Este cenário ilustra bem a pressão que a Intel está enfrentando. Não só eles precisam perseguir uma ambiciosa estratégia tecnológica em suas operações de fabricação, mas também enfrentam a perspectiva de perdas contínuas, especialmente no mercado de CPUs para data centers. A questão é se eles podem mitigar isso através do mercado de GPUs.
Há também o risco de que o mercado de GPUs em nuvem siga um caminho semelhante ao mercado de CPUs em nuvem, onde um ecossistema de software robusto para IA permite a entrada de mais participantes no mercado. Embora o design de GPUs de última geração seja complexo, com altos custos de desenvolvimento, há a possibilidade de que alguns players de peso entrem no cenário.
A AMD, por exemplo, está focando seus esforços no mercado de supercomputação exascale. O supercomputador "El Capitan" da HP, que será o mais rápido do mundo, usará aceleradores AMD MI300A. Esses aceleradores combinarão CPUs, GPUs e memória de alta largura de banda, aumentando as capacidades de IA, como modelos de linguagem.

A Amazon também entra na competição com sua GPU Trainium e o AWS Neuron SDK, oferecendo alternativas para a Nvidia. Dado o amplo alcance da AWS nos hiperescaladores de nuvem, sua entrada é considerada uma concorrência substancial.
O cenário do mercado de GPUs em nuvem está evoluindo rapidamente, com concorrentes diversificados e em expansão. A Nvidia enfrenta o desafio de manter sua posição dominante à medida que mais jogadores entram no campo, enquanto a Intel busca estratégias para enfrentar o declínio no mercado de CPUs para data centers. O futuro da computação acelerada pela IA será moldado por essas dinâmicas competitivas.
vamos abrir aspas para o chefe de datacenter da AMD
“Em GPUs, novamente adotamos uma abordagem faseada para atacar o mercado. E pensamos que a parte mais acessível do mercado seria na exascale, na extremidade mais alta. O software para ter os sistemas otimizados era mais tratável do que no mercado mais amplo de IA.”
Essa abordagem tem sido bem-sucedida, pois a AMD conseguiu assumir uma parte do mercado de supercomputação:
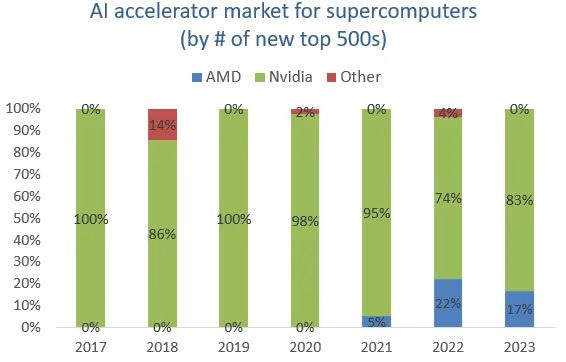
A parceria da Microsoft com a AMD no design de um chip de IA, focado principalmente em inferência para modelos já treinados, oferece à AMD uma dupla oportunidade. Ela pode ganhar mercado com suas próprias GPUs e também se destacar no desenvolvimento de chips para outras empresas que não possuem expertise em design. A Broadcom e a Marvell também exploram essa tendência. A Tesla está construindo o supercomputador "Dojo" para treinamento de IA, prometendo melhorias significativas em eficiência em relação às GPUs Nvidia. Musk pretende oferecer o Dojo como serviço, competindo com Nvidia e provedores de nuvem.
Startups também entram no cenário. A Tenstorrent, liderada por Jim Keller, apresenta processadores eficientes e programáveis, compatíveis com Pytorch. A Graphcore, do Reino Unido, trabalha em soluções de IA. A plataforma Triton da OpenAI é comparável à oneAPI da Intel, visando substituir a CUDA. O Triton facilita a programação de GPUs, expandindo para suporte da AMD.
A competição no mercado de chips para IA está acelerando, com várias empresas se posicionando para oferecer alternativas e desafiar a liderança da Nvidia. O cenário promete inovações e avanços significativos à medida que as empresas buscam dominar esse campo em rápida evolução.
A China continua sendo outro risco
A Nvidia está comercializando GPUs de menor desempenho na China devido a restrições dos EUA. Essas variantes, como o Nvidia H800, podem ser até 30% mais lentas em algumas tarefas de IA, mas ainda representam melhorias para as empresas chinesas. Além disso, um mercado negro de GPUs originais da Nvidia está emergindo na China, vendendo a preços elevados. Entretanto, há riscos, pois restrições adicionais dos EUA poderiam impactar as vendas e as receitas a longo prazo. O mercado chinês de IA é promissor e em crescimento, tornando-se tecnologicamente avançado. O CFO da Nvidia expressou preocupações sobre a perda de oportunidades a longo prazo se as restrições impedirem a venda de GPUs de datacenter para a China. A situação envolve incertezas e possíveis desafios para a Nvidia no futuro.
No geral, a empresa divulgou que cerca de 20 a 25% das receitas do datacenter são atualmente provenientes da China. Isso não é surpresa, já que os gigantes chineses da internet, como Alibaba, Tencent e Baidu, terão como objetivo fazer seu treinamento de IA em aceleradores Nvidia. Todos eles estão trabalhando em modelos avançados de IA, desde grandes modelos de linguagem até direção autônoma, e, portanto, suas demandas de GPU são obviamente substanciais. E há uma longa lista de outras empresas chinesas usando IA, desde Hikvision (câmeras de vigilância) até Bytedance (TikTok).
O Reinado da Nvidia
Naturalmente, a Nvidia não está parada. Eles permanecem focados tanto no fornecimento do melhor hardware quanto na construção adicional de seu ecossistema de software.
A referência do setor para medir o desempenho da GPU é o MLPerf, organizado pela MLCommons a cada seis meses. Este teste testa uma GPU em uma ampla variedade de cargas de trabalho de IA com reconhecimento de imagem, geração de linguagem natural e aprendizado por reforço sendo alguns exemplos. Portanto, ele mede tanto a potência da GPU quanto sua versatilidade em lidar com uma ampla variedade de tarefas. Normalmente, a maioria dos concorrentes da Nvidia não se preocupa em competir ou envia resultados para apenas um número selecionado de tarefas de IA. Crédito à Intel aqui por competir durante a última rodada, embora eles tenham enviado apenas resultados em quatro tipos de cargas de trabalho.
Os resultados mostram que o Habana Gaudi 2 da Intel teve um desempenho respeitável contra o H100 (arquitetura Hopper) da Nvidia na ResNet, uma tarefa de classificação de imagem, com desempenho inferior apenas com cerca de 15 a 20%. No entanto, em outras tarefas, obliterado. Então, apesar da conversa de muitos concorrentes de que eles têm soluções competitivas, essa é a razão pela qual todos atualmente estão perseguindo GPUs Nvidia. abaixo segue o ultimo resultado do teste:
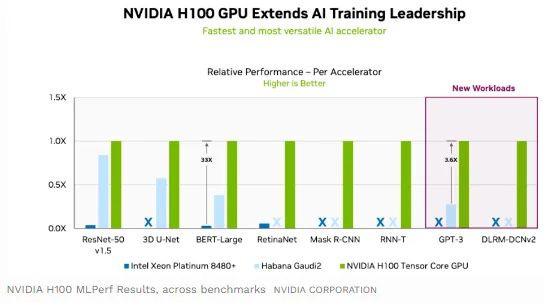
Em junho de 2022, o Google conseguiu vencer a Nvidia em cinco testes, embora não tenham enviado resultados para os outros. O que provavelmente significa que o TPU deles não teve um desempenho tão bom nessas tarefas. No entanto, observe aqui que o Google conseguiu vencer o A100 (arquitetura Ampere) da Nvidia, que já foi lançado no final de 2020. Alguns meses depois, em 2022, a Nvidia lançou o acelerador H100.

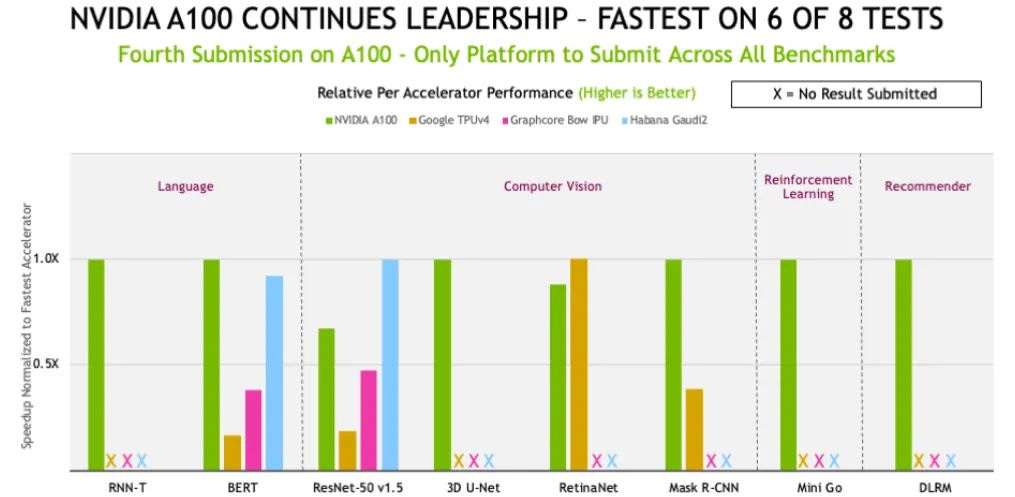
Então, foi basicamente durante a última rodada, quando o A100 competiu, que ele foi derrotado:

Em uma base por acelerador, a Nvidia observou que o A100 na verdade ainda ganhou 6 de 8 testes naquele ano:
E o mais recente H100 da Nvidia é novamente muito superior em comparação com o A100. Você pode ver que a Nvidia tem focado seus esforços na expansão das capacidades da GPU para o manuseio de modelos baseados em transformadores, o que acelera o treinamento de grandes modelos de linguagem, como o ChatGPT. Isso é ilustrado nos benchmarks BERT abaixo.
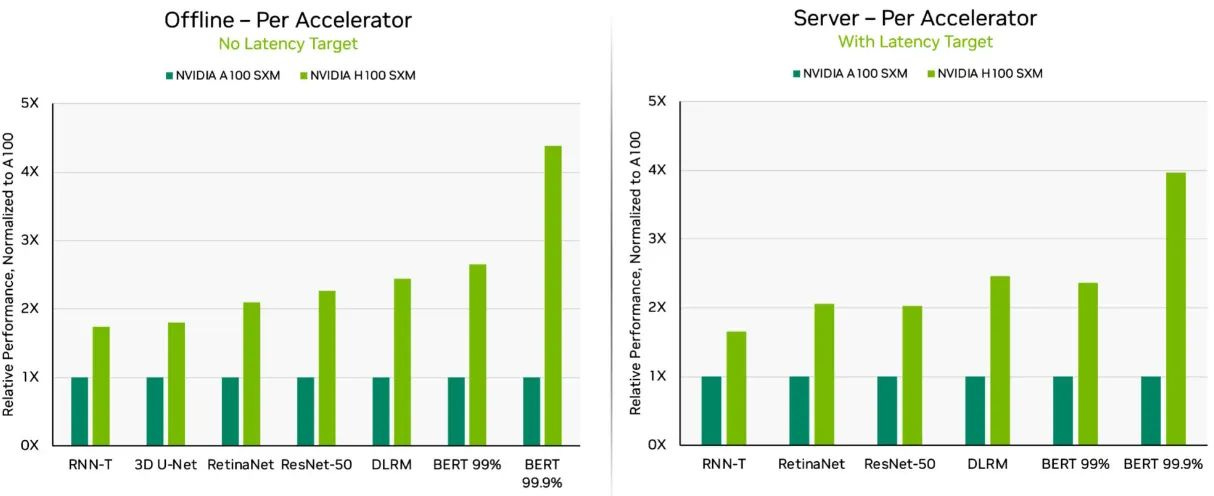
E a noticia ruim para os concorrentes é que o desempenho do H100 continuará a melhorar.
Abre aspas de novo para Ian Buck, atual chefe de computação de alto desempenho da Nvidia
“O outro ponto interessante é que não paramos depois de enviarmos um novo produto. Investimos continuamente em otimizações de software. Contratei milhares de engenheiros de software em toda a empresa. A Nvidia, neste momento, tem mais engenheiros de software do que engenheiros de hardware. E então, depois de fazermos a primeira rodada de benchmarking em algo como Hopper, nós o melhoramos continuamente. Ampere ao longo de sua vida útil, viu uma melhoria de 2,5 a 3x desde a primeira vez que nos submetemos ao MLPerf.”
Projetar esses chips de alta qualidade é incrivelmente caro, custando centenas de milhões de dólares. E a Nvidia, com seus bolsos profundos e ampla base de clientes, só tem acelerado a cadência desse ciclo de P&D ( pesquisa & desenvolvimento ). Assim, criando uma barreira adicional para que a concorrência seja superada. e mais uma vez Ian Buck explica, abre aspas:
“Também aceleramos o roteiro da GPU. Então, costumávamos fazer uma classe GPU 100 a cada 3 anos, agora estamos baixos para 2 anos e, em alguns casos, um ciclo de 18 meses. Jensen já falou sobre Hopper Next e essa linha do tempo.”
Certos jornalistas e analistas têm comentado que o MI300 da AMD contém mais memória do que o H100 da Nvidia. No entanto, a Nvidia tem um bom truque na manga aqui para dobrar a capacidade de memória. Mais uma vez, Ian Buck fornece os detalhes:
“O que Hopper fez que foi tão revolucionário, fizemos algo chamado FP8, uma representação de ponto flutuante de 8 bits. Obviamente, a computação em 8 bits é mais rápida do que a computação em 16. Além disso, o tamanho da memória é metade do que você teria em 16 bits, que é o que tínhamos antes. E é muito trabalhoso fazer isso realmente funcionar. Para descobrir como manter as coisas dentro do alcance desses 8 bits.”
Além disso, a Nvidia continua com a construção de seu ecossistema de IA..
O portfólio de produtos Nvidia AI mais amplo
À medida que as cargas de trabalho de IA passaram de serem executadas em uma GPU para milhares de servidores interconectados, a Nvidia decidiu adquirir a Mellanox, uma empresa israelense focada na interconexão de alto desempenho para o datacenter. A empresa naquela época tinha margens brutas atraentes de 69%, estava crescendo a uma taxa de 26% e já estava gerando mais de US$ 1 bilhão em receitas anuais.
Jensen Huang, CEO da Nvidia, comentando no momento da aquisição:
“No futuro, queremos otimizar as cargas de trabalho em escala de datacenter em toda a pilha, desde o nó de computação até a rede e o armazenamento. Por esse motivo, a tecnologia de interconexão em escala de datacenter de sistema para sistema da Mellanox é importante para nós. Acreditamos que nossa plataforma será mais forte e fornecerá o melhor desempenho possível para os clientes do datacenter.”
A Nvidia também entrou recentemente no mercado de CPUs, com suas CPUs Grace. Da Anandtech:
“Grace foi projetado para preencher a lacuna do tamanho da CPU nas ofertas de servidores de IA da Nvidia. Nem todas as cargas de trabalho são puramente vinculadas à GPU, nem que seja porque uma CPU é necessária para manter as GPUs alimentadas. As ofertas atuais de servidores da Nvidia, por sua vez, normalmente dependem dos processadores EPYC da AMD, que são muito rápidos para fins gerais de computação, mas não têm o tipo de IO de alta velocidade e otimizações de aprendizagem profunda que a Nvidia está procurando.”
A interconexão de alta velocidade entre os vários processadores de servidor da Nvidia é estabelecida com o NVLink, uma tecnologia de comunicação de alta largura de banda e baixa latência desenvolvida pela Mellanox.
DGX Cloud é um serviço de treinamento de IA para alugar servidores Nvidia DGX pela nuvem. Você também pode acessar este serviço através das nuvens Microsoft, Google e Oracle.
Do site da Nvidia:
“Nosso DGX GH200 foi projetado para lidar com modelos de classe terabyte para sistemas de recomendação massivos, IA generativa e análise de gráficos, oferecendo 144 terabytes (TB) de memória compartilhada com escalabilidade linear para modelos gigantes de IA.”
A empresa também está adicionando mais recursos de software à sua gama de produtos. O AI Foundations permite que os clientes ajustem modelos pré-treinados com seus próprios dados, oferecendo reduções maciças no tempo de treinamento, pois você não precisa treinar um novo modelo de IA do zero. A ideia soa muito semelhante à Hugging Face’s, uma comunidade para desenvolvedores compartilharem modelos de IA. Alguns exemplos de como as fundações de IA podem ser usadas:
A Nvidia também tem trabalhado em uma plataforma automotiva autônoma, onde a Mercedes e a Jaguar Land Rover são os primeiros clientes proeminentes. O pipeline nesta unidade de negócios é de US$14 bilhões, então isso deve se transformar em um negócio anual de receita multibilionária ao longo do tempo. Os OEMs podem escolher entre a oferta aqui como quiserem, por exemplo, podem comprar puramente o hardware ou também podem usar o software para treinamento de dados. Você poderia puramente treinar um modelo autônomo na simulação da Nvidia e depois ajustá-lo ainda mais em seus veículos em um sistema MobilEye, por exemplo.

O sistema autônomo em um veículo é executado em um superchip Thor:
Assim como a Nvidia construiu um gêmeo digital de cidades e estradas para treinar sistemas automotivos autônomos, eles estão fazendo o mesmo para gerenciar fábricas. A imagem abaixo mostra Jensen Huang participando de uma reunião da equipe BMW sobre o design virtual de sua nova fábrica de EV, usando o software Omniverse da Nvidia:
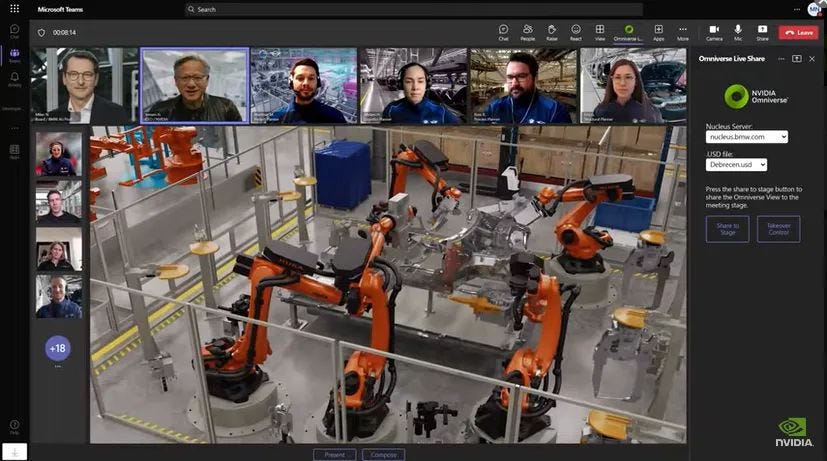
Atualmente, o software está gerando apenas receitas anuais em centenas de milhões de dólares. Mas isso pode se tornar um impulsionador de crescimento mais interessante daqui para frente.
O que vem a seguir em grandes modelos de linguagem?
Ian Buck também compartilhou algumas ideias sobre o que vem a seguir na IA na recente conferência Rosenblatt. Em primeiro lugar, ele entrou nos limites dos tamanhos dos modelos de rede neural. O principal fator limitante aqui é o tempo de treinamento - quanto maior o modelo, mais tempo leva para treinar. Portanto, os desenvolvedores construirão modelos que permanecerão praticáveis para treinar. Isso normalmente significa que você deve ser capaz de treiná-lo em um ou dois meses. Se você passar por isso, sua capacidade de inovar fica prejudicada, pois você quer a capacidade de atualizar regularmente seu modelo.
Outras inovações para melhorar ainda mais as redes neurais incluem matemática mais sofisticada. abre aspas para Ian Buck:
“Estamos continuamente ajustando a inteligência em cada camada, tornando-as mais otimizadas, mais inteligentes em cada camada, o que aumenta a complexidade. Isso nem sempre é capturado no número de parâmetros, porque cada camada tem um monte de matemática e cálculos em vez de ser apenas uma conexão ingênua. Os cérebros humanos se comportam de forma semelhante. Temos diferentes tipos de neurônios para processamento de visão versus audição versus memória. Quanto mais tempo você jogar com algo como ChatGPT, você pode fazer com que ele esqueça a conversa anterior, e ela vai derivar. E isso é uma função da duração da sequência, quanto das informações da conversa podemos manter em sua loja. O comprimento da sequência aumenta significativamente o tamanho da computação. Estamos vendo modelos se integrarem mais profundamente aos bancos de dados de inteligência e aplicando a IA ao próprio banco de dados. Bancos de dados vetoriais são super interessantes.”
A inferência será o mercado maior
Atualmente, as taxas de crescimento projetadas do mercado de AI variam de 40 a 50%. A previsão abaixo, da Marqual, estava prevendo uma CAGR de 17%, mas esta foi feita antes da popularização de grandes modelos de linguagem com o ChatGPT. O consenso, no entanto, é que a inferência continuará sendo o mercado maior dos dois versus o treinamento de IA. O gráfico abaixo ilustra bem isso:
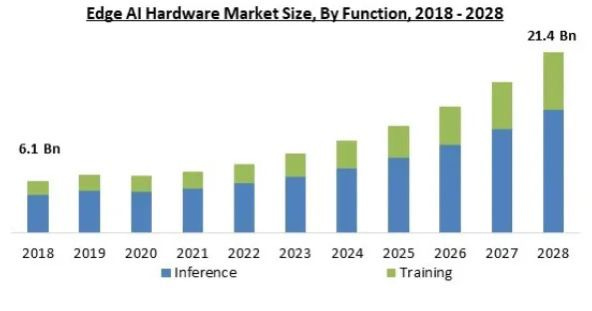
A inferência não ocorrerá apenas na nuvem, mas também na borda da rede, ou seja, o poder de computação instalado mais perto do consumidor final, por exemplo, no seu smartphone ou no seu carro.
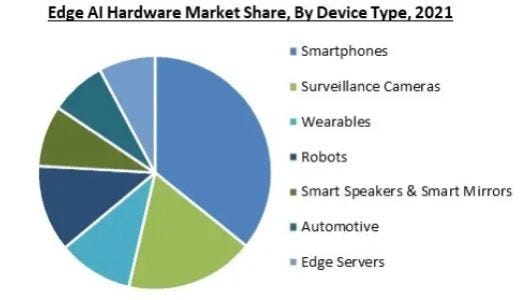
Este mercado é mais competitivo do que o treinamento de IA, onde a Nvidia domina. Todos os tipos de chips são usados aqui, de GPUs a CPUs e FPGAs. Como resultado, uma gama mais ampla de semi-jogadores poderá competir nesta arena com a Nvidia, incluindo Intel, AMD, Broadcom, Apple, NXP e Lattice.
Como a Inferência fornecerá a próxima etapa de crescimento?
O mercado de inferência de IA, que executa modelos pré-treinados no mundo real, é maior que o de treinamento. Ele abrange tanto datacenters quanto dispositivos na borda da rede. A concorrência é mais intensa aqui, incluindo empresas como Intel, AMD, Apple e startups. Com modelos de linguagem maiores surgindo, pode ser necessário chips mais poderosos. Isso pode proporcionar uma oportunidade de crescimento para a Nvidia expandir sua presença nesse mercado. Jensen Huang discutiu os desafios e benefícios de modelos maiores de linguagem na borda no conference call recente.
A criação de grandes modelos de linguagem envolve destilar versões menores a partir desses modelos maiores por meio de um processo chamado destilação. Modelos maiores têm alta generalidade e capacidade de abordar uma ampla variedade de perguntas e tarefas. Modelos menores, derivados dos maiores, podem ter excelentes capacidades em habilidades específicas, mas podem não generalizar tão bem. A destilação permite que os recursos dos modelos maiores sejam usados em dispositivos de computação menores e diversos, preservando habilidades específicas de interesse.
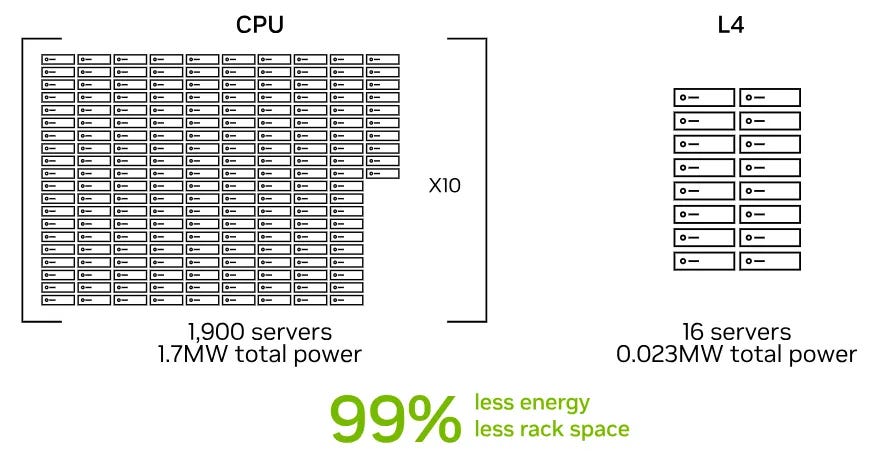
A crescente necessidade de executar modelos mais versáteis em ambientes de borda implica na demanda por chips mais potentes. A Nvidia tem respondido a essa demanda lançando GPUs direcionadas para o mercado de inferência. O ritmo da inovação nesse setor provavelmente continuará aumentando.
Um exemplo é o lançamento recente das GPUs da série L4, que possuem preços mais baixos em comparação com as GPUs das séries A e H100. A análise realizada pela Nvidia mostrou que as GPUs da série L4 superaram significativamente as CPUs em cargas de trabalho de vídeo de IA.
O atual boom no treinamento de AI
O desempenho do datacenter da Nvidia tem sido nada menos que extraordinário. Enquanto a empresa anteriormente colocou um guidance de cerca de US$ 8 bilhões em receitas de datacenter neste trimestre, as receitas chegaram a mais de US$ 10 bilhões, pois seus fornecedores conseguiram aumentar a capacidade melhor do que o esperado.

A NVIDIA está experimentando uma forte demanda por sua plataforma de datacenter, especialmente das grandes empresas de nuvem e internet. O CFO da Nvidia mencionou que essa demanda se estende até o próximo ano, e eles estão trabalhando para aumentar o fornecimento em parceria com seus fornecedores.
As grandes empresas de nuvem estão realizando uma transição geracional para atualizar suas infraestruturas de datacenter usando sistemas HGX da NVIDIA, que são o resultado de duas décadas de inovação em várias áreas tecnológicas. As instâncias alimentadas pelas GPUs NVIDIA H100 Tensor Core estão sendo disponibilizadas em provedores como AWS e Microsoft Azure, entre outras.
As empresas de consumo da internet também estão investindo em infraestrutura de datacenter para IA, e isso está trazendo retornos significativos. Por exemplo, a Meta (Facebook) destacou um aumento de mais de 24% no tempo gasto no Instagram devido às recomendações de IA.
A receita da NVIDIA está sendo impulsionada principalmente pelos grandes provedores de serviços em CLOUD, seguidos pelas empresas de internet de consumo e, por último, clientes corporativos e de computação de alto desempenho.
No entanto, a demanda desproporcional está causando dificuldades para os players menores, que estão lutando para obter alocações de GPU devido ao acesso preferencial dado às grandes empresas de Cloud e internet.
A mais recente plataforma HGX da Nvidia é uma combinação de oito GPUs H100, o estado atual da arte, conectadas ao NVLink em quatro NVSwitches. 32 dessas plataformas podem ser conectadas em rede, dando um total de 256 GPUs capazes de atuar como uma unidade.

Jensen Huang, fundador da Nvidia, deu mais detalhes sobre a arquitetura HGX e o componente H100, destacando que os H100s, embora chamados de "chips", na verdade são componentes de sistema maiores conhecidos como HGXs. Esses HGXs possuem cerca de 35.000 peças, pesam cerca de 70 libras (aproximadamente 31,75 kg) e contêm quase 1 trilhão de transistores em combinação. A montagem dos HGXs requer robôs devido ao peso, e um supercomputador é necessário para testar um supercomputador baseado nesse componente.
A principal razão para a escassez de GPUs da Nvidia é a falta de capacidade de fabricação, especialmente em tecnologias como HBM (DRAM empilhada em 3D) e CoWoS (embalagem avançada). A Nvidia está trabalhando para aumentar a capacidade em parceria com seus fornecedores e qualificando capacidades e fornecedores adicionais em várias etapas do processo de fabricação, incluindo embalagem CoWoS.
A Nvidia está tomando medidas para construir uma cadeia de suprimentos independente da TSMC, envolvendo empresas como UMC, Amkor e SPIL (embalagem e testes). A UMC, por exemplo, está expandindo sua capacidade de produção de interposição de silício, o que poderia aliviar a pressão de fornecimento no processo CoWoS.
Para ilustrar como o HBM é conectado a um dado em um pacote CoWoS, você pode consultar o diagrama disponível no WikiChip.
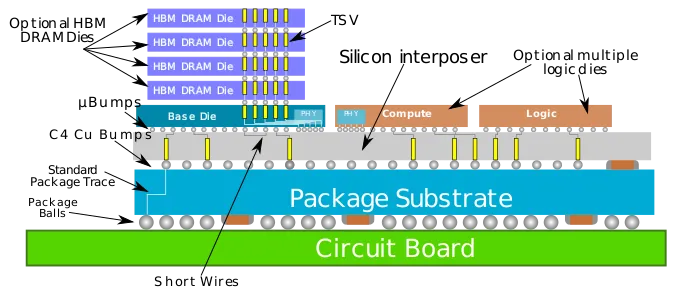
Resumindo, Jensen Huang explicou que os H100s são componentes maiores chamados HGXs, com uma arquitetura complexa. A escassez de GPUs se deve à falta de capacidade de fabricação, e a Nvidia está trabalhando com parceiros para aumentar a capacidade. A empresa também está buscando diversificar sua cadeia de suprimentos para reduzir a dependência da TSMC. Isso inclui expansão da capacidade de interposição de silício pela UMC.
a Nvidia está tomando várias medidas para abordar a escassez de GPUs e atender às demandas do mercado. Além de aumentar a capacidade de produção e diversificar a cadeia de suprimentos, eles também estão lançando novos chips de IA para atender a diferentes tipos de cargas de trabalho.
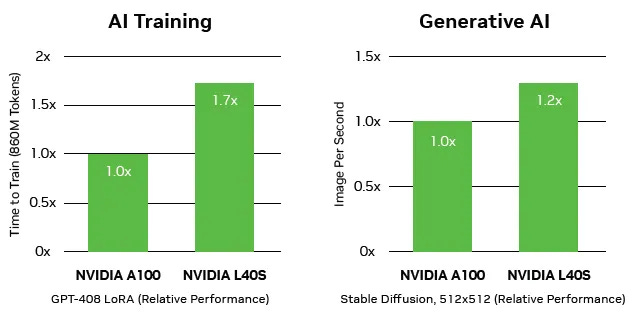
Um desses novos chips é o L40S, que foi projetado para atender a um conjunto específico de aplicações. Jensen Huang explicou que enquanto o H100 foi projetado para lidar com modelos e processamento de linguagem em larga escala, o foco do L40S é mais voltado para ajustar e otimizar modelos pré-treinados. Ele possui um motor de transformação e oferece alto desempenho, permitindo que vários desses chips sejam usados em um único servidor.
Segundo os testes realizados pela Nvidia, o L40S mostrou um desempenho superior em relação à geração anterior do chip, o H100 (também conhecido como A100), especialmente em cargas de trabalho específicas para as quais ele foi projetado.
Portanto, a Nvidia está abordando a escassez de GPUs não apenas aumentando a capacidade de produção, mas também introduzindo novos chips como o L40S, que são otimizados para atender a necessidades específicas e oferecer um desempenho melhorado em determinados tipos de trabalho. Isso demonstra a abordagem multifacetada da empresa para lidar com os desafios do mercado.
O ecossistema de software da Nvidia desempenha um papel fundamental em sua oferta de IA e sua posição dominante no mercado de treinamento de IA. A empresa está oferecendo uma variedade de soluções e produtos que se estendem para além das GPUs, incluindo plataformas de desenvolvimento e software de ponta a ponta.
Um destaque é a plataforma NVIDIA NeMo, que permite que as empresas construam modelos de linguagem personalizados para diversos serviços avançados de IA, como Chatbots e resumo de texto, diretamente da Snowflake Data Cloud.
Além disso, a Nvidia está envolvida em parcerias estratégicas com empresas como a WPP, maior organização de serviços de marketing e comunicação do mundo, para desenvolver mecanismos de conteúdo usando o NVIDIA Omniverse, que integra a IA generativa na criação de conteúdo 3D.
Dado todo o esforço da AMD para lançar o MI300, que é projetado para competir em algumas cargas de trabalho de treinamento de IA. A AMD também está construindo seu ecossistema de software, incluindo integração com frameworks populares como o PyTorch como falei no começo do artigo.
A Nvidia reconhece a concorrência e está acelerando sua cadência de desenvolvimento de produtos, passando de lançamentos a cada dois anos para um ciclo de 18 meses, para continuar a evoluir seus produtos e manter sua liderança no mercado.
A ênfase da Nvidia em seu amplo ecossistema de software é notável, com a plataforma NVIDIA AI Enterprise servindo como um tempo de execução abrangente para aprendizado de máquina, desde o processamento de dados até o treinamento e a implantação de modelos. Esse ecossistema é continuamente atualizado e otimizado para fornecer um conjunto abrangente de ferramentas para empresas que trabalham com IA.
Com base nesses fatores, é esperado que a Nvidia mantenha sua posição dominante no mercado de treinamento de IA no curto prazo. No entanto, com o surgimento de concorrentes fortes e a evolução constante do campo, espera-se que haja uma competição mais intensa a longo prazo. Atualmente, a Nvidia detém uma participação de mercado estimada em torno de 75%, mas é provável que haja mudanças nessa dinâmica à medida que a indústria evolui.
A demanda por GPUs e hardware de IA é notavelmente alta, com muitas empresas e startups buscando adquirir recursos para treinamento e implantação de modelos de aprendizado de máquina e inteligência artificial. Essa demanda está superando a capacidade de produção da Nvidia e de outras empresas no setor.
O ciclo de vida médio de uma GPU de datacenter é cerca de 3 anos. No entanto, a intensidade da demanda, a evolução tecnológica e a concorrência podem influenciar esses ciclos. Com aumentos intermitentes na demanda à medida que os modelos de IA se tornam mais complexos e as necessidades crescem, parece plausível, especialmente considerando o aumento na utilização de IA em uma variedade de setores.
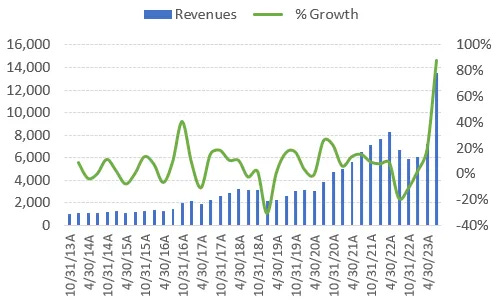
A indústria de semicondutores é cíclica, mas a demanda constante por IA pode suavizar essas flutuações. O futuro da Nvidia e da IA dependerá da evolução tecnológica, da demanda do mercado e da competição.
Isso significa que, se a Nvidia fizer cerca de US$ 55 a 60 bilhões em receitas de datacenter nos próximos doze meses, isso seria cerca de 23% dos gastos globais com capex de datacenter. Esse é um número extraordinariamente alto e não sustentável por longos períodos de tempo.
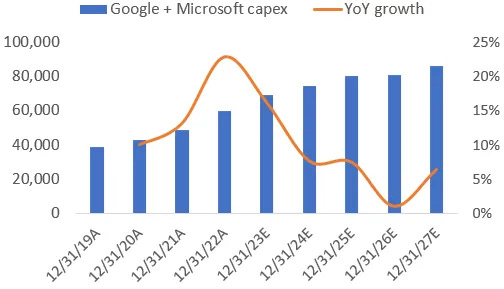
Antes desse boom da IA, as receitas do datacenter da Nvidia eram de cerca de 6% dos gastos com capex do datacenter. A única maneira de investimentos elevados como esses serem sustentáveis é se um ou mais aplicativos LLM virais encontrarem seu caminho para o mundo real e começarem a gerar dezenas de bilhões de dólares em receitas. Podemos pensar em experiência de Pesquisa do Google ou no Copiloto da Microsoft como potenciais candidatos aqui.
Durante uma teleconferência, Frank Slootman, CEO da Snowflake, abordou investimentos em IA em resposta a uma pergunta de um analista da Evercore. O analista perguntou se os executivos reconhecem a necessidade de um investimento mais significativo em IA agora, comparado a 12 meses atrás.
Slootman respondeu que muitos ainda estão em uma fase exploratória e experimental em relação aos modelos de linguagem e que estão tentando entender o escopo real e o potencial desse campo. Ele indicou que a dimensão da necessidade de investimento ainda não está clara e levará tempo para se obter uma leitura precisa sobre os recursos necessários.
Ele mencionou a importância histórica da pesquisa, que geralmente tinha um modelo de negócios forte para financiá-la (como o caso do Google). Porém, na IA, a falta de um modelo de negócios sustentável é uma preocupação, e a questão de como financiar os avanços e esforços contínuos em IA é crucial. Slootman destacou que desencadear o desenvolvimento da IA sem ter um modelo de negócios sólido pode levar a problemas, já que as pessoas perderiam o interesse rapidamente se não houvesse um retorno tangível.
Resultado de NVIDIA
Dado que a empresa continua a ver um mercado apertado com o crescimento continuando no próximo ano e que os grandes players de cloud e internet tenham as alocações de GPU de que precisam, provavelmente veremos uma queda na demanda até entrarmos em um ciclo de substituição ou expansão adicional. No entanto, o mercado já está antecipando isso em grande medida e no último trimestre, pela primeira vez na história dos semicondutores, vimos uma empresa guiar as receitas $4 bilhões acima do consenso; com expectativas reconhecidamente mais altas neste trimestre.

A Nvidia está negociando 31,41x o EPS dos próximos doze meses, o que é conservador se você acredita que a IA será uma história de crescimento convincente durante as próximas décadas e a Nvidia continuará sendo líder nessa transição.

Pelo fechamento de sexta-feira em Wall Street ($460,2), com o consenso projetando um CAGR de 13,9% até 2028Q1 da receita e pelo preço de fechamento nos da um crescimento perpetuo implícito de 6,9% considerando 10% de WACC. Algumas analises projetam um wacc de 14% ( Damodaran ), acho um exagero, para um empresa que é caixa liquido, com um custo de equity muito maior que um custo de debito.. fazer essa recompra de ações me parece assertivo no momento para melhorar a estrutura de capital da empresa.
abaixo o modelo de sensibilidade eixo y ( wacc ), eixo x ( crescimento perpetuo )

Compilei uma cesta de empresas de tecnologia de crescimento de qualidade, aquelas normalmente vistas pelos analistas como sendo empresas de alta qualidade, dominando seus nichos, enquanto são expostas a taxas de crescimento atraentes. Isso ilustra bem que os múltiplos da Nvidia não são um exagero. Apesar de ter as melhores taxas de crescimento projetadas e algumas das melhores margens, as ações são negociadas em um múltiplo de PE não tão exigente nos próximos doze meses.
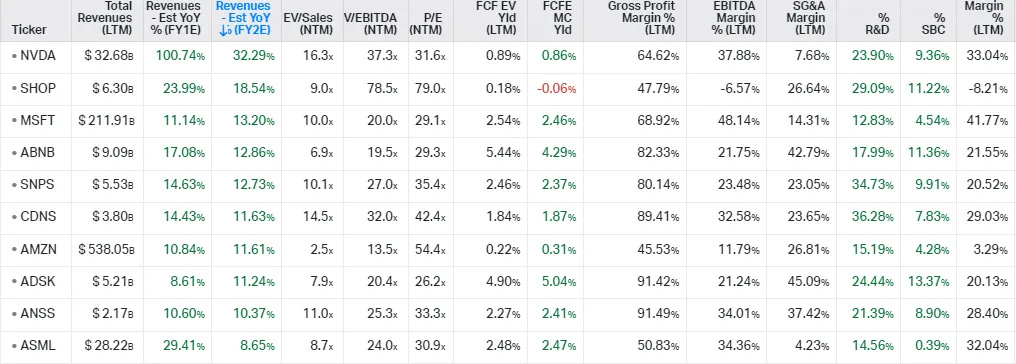
Obviamente, a história de longo prazo deve ser atraente para a Nvidia, embora esteja esperado algum recuo cíclico em algum momento. No entanto, olhando para o múltiplo de mercado já está antecipando isso até certo ponto. Afinal, se o mercado acreditasse nos números do lado da venda, essas ações estariam sendo negociadas em 80x ou mais como o Shopify, dando um preço de ação acima de US$ 1.100.
A empresa também aumentou a receita. Ele espera vendas no terceiro trimestre em US$ 16 bilhões, 28%, acima da estimativa do analista de US$ 12,5 bilhões. usando a relação PEG, que usa uma proporção do EPS / crescimento de EPS a prazo de 1 ano. O P/E no caso é de 107.11

Sua taxa de crescimento de EPS é de 3,2 2023y para 10,196 2024y o que nos da uma taxa de crescimento de 218%.

Considerando o múltiplo corrente que é o maior temos Um PEG de 0,49 que é <1. O lendário investidor Peter Lynch popularizou essa métrica e considerou uma ação subvalorizada se essa proporção estivesse abaixo de 1.
O mercado de datacenters tem sido obviamente o forte impulsionador de crescimento para a Nvidia.

Os números de consenso já estão refletindo isso:

A Nvidia é obviamente uma ação cara, porem olhando as projeções com EPS de consenso 24.14x 2026 o preço parece melhor que antes do resultado. Temos uma empresa incrivelmente forte com taxas de crescimento de primeira linha que devem estar ao norte de 20%.
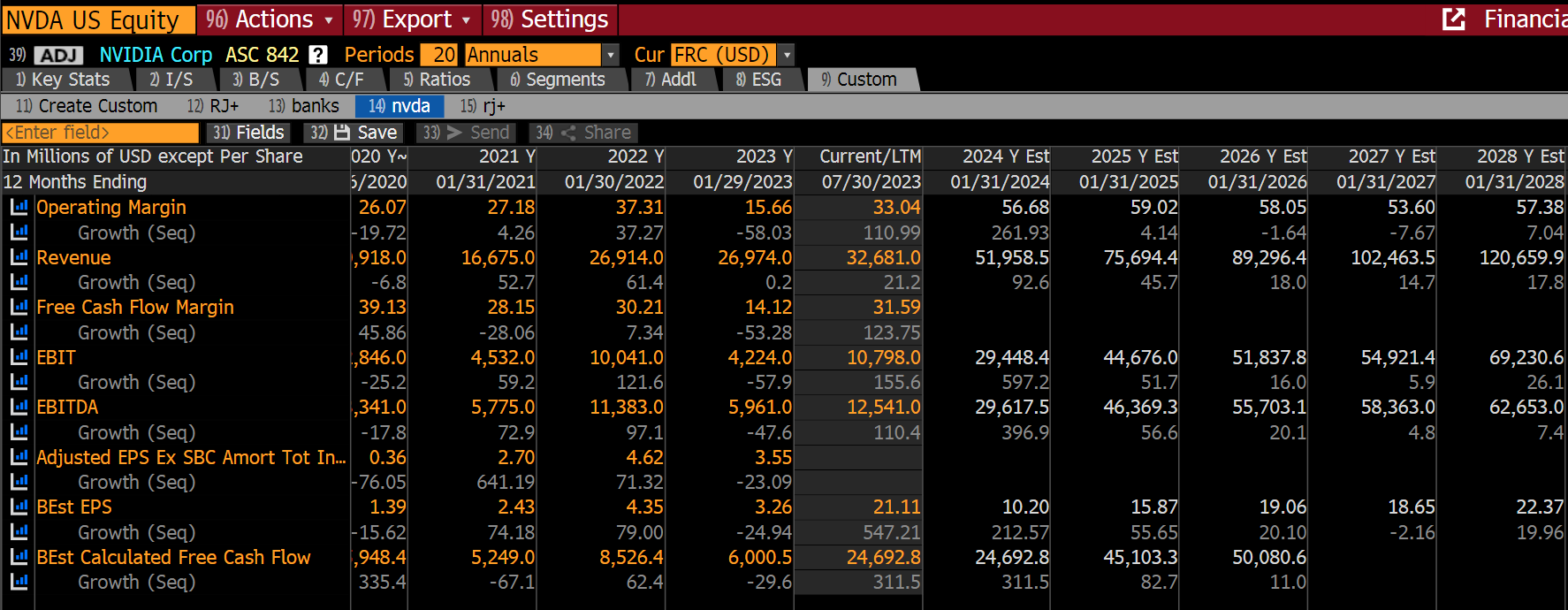
A Nvidia é claramente um negócio muito intensivo em P&D e isso não será fácil de replicar para a concorrência. Há também um potencial de aumento significativo em suas margens brutas, embora o consenso já esteja modelando isso.


Tanto para Nvidia quanto para AMD, você não está pagando mais do que na história recente:
