MacroChronics WEEK AHEAD 13 (28/5/2023)

As linhas vermelhas mostram um aumento nas atualizações de estimativa de analistas. Tais picos ascendentes geralmente são um prelúdio para o crescimento acentuado dos lucro e o fundo dos ciclos. No entanto, o gráfico mostra uma grande divergência no otimismo dos analistas em relação ao leading indicador econômico.

Após 45 dias de movimento lateral, o mercado quebrou a consolidação o que permitiu mais uma serie de altas para o índice SPX.
Essa quebra da consolidação provocou uma enorme cobertura de short e uma corrida para comprar o índice do setor de tecnologia, com as mega-caps novamente liderando o caminho.
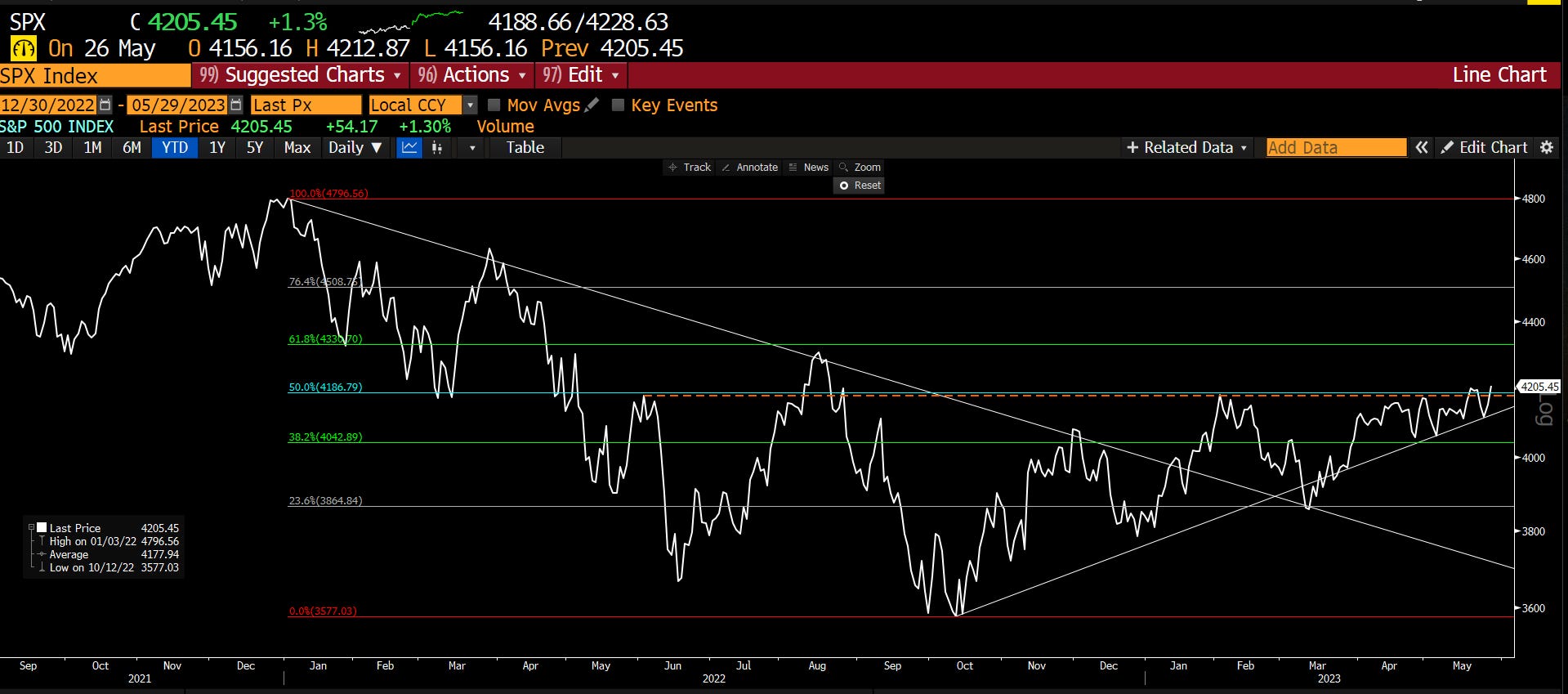
Esta rompimento é muito bullish por duas razões: Primeiro, o mercado concluiu uma retração de 50% do declínio de 2022, o que prepara o terreno para um novo avanço. Em segundo lugar, o rompimento confirma a tendência de alta que começou a partir das mínimas de outubro. Embora existam muitas razões para um bear market, o mercado sugere que essas preocupações estão equivocadas, por enquanto.
O próximo nível de resistência para o mercado é o nível de retração de Fibonacci de 61,8% em 4330, que está um pouco acima da alta de julho de 2022 de 4305,20. Uma quebra acima desses níveis, levará os índices para uma recuperação total do declínio de 2022.
Há muitas diferenças entre o ambiente econômico atual e os cenários de ‘soft lending’ passados, os mais importantes são a inflação e as taxas de juros. Como observado, a economia nunca teve um resultado de “recessão suave” quando ambos dos índices estavam acima de 5%.
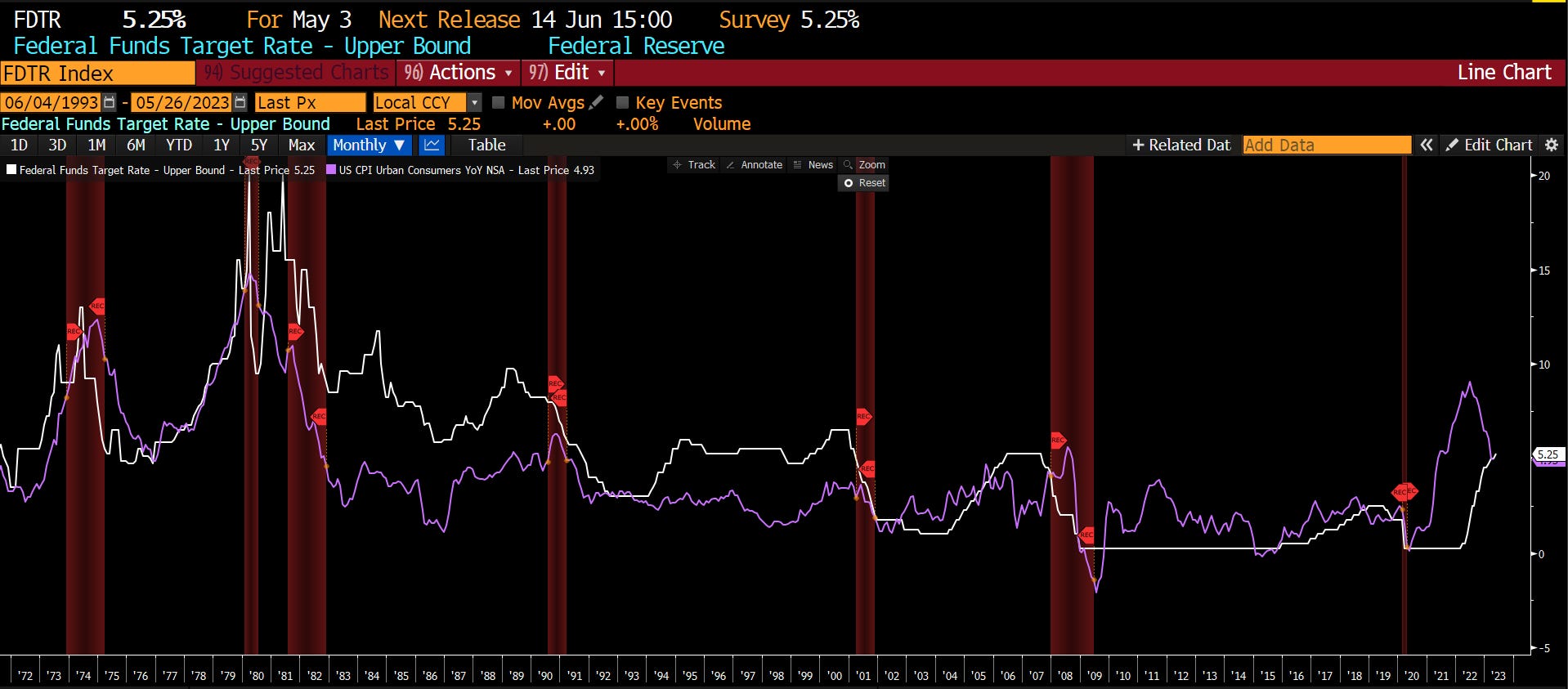
O risco mais significativo para os investidores continua sendo a capacidade dos balanços corporativos atenderem às expectativas de lucro do mercado. Embora a mídia muitas vezes afirme que “as ações não são a economia”, a atividade econômica cria receitas e ganhos corporativos. Como tal, as ações não podem crescer mais rápido do que a economia por longos períodos.
O que temos até agora nos mercados é uma ‘’corrida do ouro’’, onde esse hype de AI veio com tanta força, que está colocando vários temas importantes do mercado para um segundo plano. Então resolvi estudar a fundo o que é esse fenômeno e o quão profundo pode ser essa mudança nos próximos anos que estão fazendo os investidores e analistas agirem como se não houvesse amanhã. Aos shorts deixo uma frase muito famosa de John Maynard Keynes
“Os mercados podem permanecer ilógicos por mais tempo do que você pode permanecer solvente.”
INTELIGÊNCIA ARTIFICIAL (IA)/ MACHINE LEARNING (ML)
IA é um termo tão solto, uma palavra mágica que simplesmente significa algum tipo de caixa preta orientada matematicamente. Geralmente é pensado como um mecanismo de computação que pode fazer uma tarefa ou melhor do que um humano, impulsionado por um "cérebro" (motor de IA) que toma decisões. Essencialmente, a IA é um monte de algoritmos matemáticos internos que se interconectam e se combinam em um grande algoritmo (o modelo geral de IA). Estes pegam uma entrada, fazem lógica (a caixa preta) e enviam de volta uma saída.
No nível mais alto, a IA até agora tem sido a Inteligência Estreita Artificial (ANI), uma forma mais fraca de IA que é afiada para concluir uma tarefa específica. Como visto nos últimos meses, estamos nos aproximando rapidamente da Inteligência Geral Artificial (AGI), uma forma mais forte de IA que pode executar uma ampla gama de tarefas e pode pensar abstratamente e se adaptar. A AGI é o Santo Graal de muitos pesquisadores de IA.
Hoje, a IA assume muitas formas, como Machine learning (aprendendo com o passado para prever o futuro), Visão Computacional (identificando estrutura em vídeo ou imagens), Fala para Texto/Texto para Fala (convertendo áudio em texto e vice-versa), Sistemas Especialistas (motores de decisão altamente aperfeiçoados) e Robótica (controlando o mundo real Eu geralmente resumo tudo isso como "AI/ML" para incluir ambos os lados da equação (e espelhar a dualidade de outros termos relacionados, como dados estruturados vs não estruturados, ou aprendizado supervisionado vs não supervisionado). Vamos nos concentrar principalmente no lado do ML aqui.
Houve uma série de avanços nos últimos anos de:
Um aumento maciço de computação e paralelização (graças a hiperescaladores de nuvem, GPUs e outros chips AI/ML especializados), o que, por sua vez, aumenta a quantidade de dados de treinamento que podem ser processados enquanto acelera maciçamente o tempo de treinamento. Isso leva a modelos maiores, o que aumenta a complexidade geral de suas decisões e a dimensionalidade dos dados com os quais pode lidar.
A IA é um discípulo orientado pela pesquisa à medida que novos modelos são concebidos e testados, e novos métodos estão frequentemente substituindo o antigo como um "passo" de capacidades. Novos avanços na modelagem ML (Transformadores, GANs, Difusão) não apenas melhoraram muito as capacidades e o desempenho, mas também ampliaram o paralelismo - permitindo que os modelos treinem sobre os dados de uma só vez, em vez de linearmente.
A ciência de dados está se democratizando, entre modelos de código aberto compartilháveis, fluxos de trabalho automatizados (AutoML) e plataformas de colaboração mais amplas (como HuggingFace, um repositório de modelos de código aberto).
Tudo isso se combina no rápido avanço que estamos vendo agora a céu aberto. Modelos de ponta estão iterando e melhorando rapidamente, e estão sendo combinados e usados de novas maneiras. Os mecanismos de IA também estão se tornando multimodais, capazes de trabalhar com mais de um formato (texto, imagem, vídeo, áudio, etc.). Tudo isso está gerando muita emoção "súbita" sobre a IA (uma década de construção de capacidades que aparentemente surgiram de uma só vez).
Infelizmente para nós, investidores, esses últimos avanços em IA Generativa e Large Language Models (LLMs) orientados por bate-papo são mais públicos ( voltados para o consumidor) do que a maioria dos outros avanços de IA acontecendo, então o ciclo de hype em torno de todas as coisas "IA" decolou ultimamente. Além das IAs Generativas, eu também jogaria a direção autônoma baseada em EV neste balde voltado para o consumidor, que também teve muito hype nos últimos anos, o que se transformou em promessas continuamente não cumpridas. Vale a pena ter algum cuidado com a IA, mas saiba que o hype é real, e o potencial desses modelos de IA de ponta é palpável. No mínimo, estamos no precipício de uma nova era de aumentos de produtividade da assistência virtual e automação. Mas à medida que esses motores amadurecem, combinam e se integram mais com outros, de repente parece que a AGI está à nossa porta.

Machine learning ( ML )
ML é o subconjunto da IA que é treinado em dados históricos passados para tomar decisões ou prever resultados. Em geral, o ML processa muitos dados antecipadamente em um processo de treinamento, analisando-os para determinar padrões dentro dele, a fim de derivar previsões futuras. Com o surgimento de modelos melhores, hardware aperfeiçoado (GPUs e chips especializados de hiperescaladores) e melhorando continuamente a escala e o desempenho dos hiperescaladores em nuvem, o potencial do ML agora está aumentando muito. Os modelos de ML podem tomar decisões, interagir com o mundo (através de texto, voz, bate-papo, áudio, visão computacional, imagem ou vídeo) e agir.
ML é extremamente útil para:
processamento de conteúdo não estruturado (texto, imagens, vídeo) para extrair significado, entender a intenção e o contexto
reconhecimento de imagem ou vídeo para isolar e identificar objetos
tomar decisões pesando fatores complexos
categorizar e inserir em grupo (classificação)
reconhecimento de padrões
reconhecimento de idiomas e tradução
processe dados históricos para isolar as tendências que ocorrem e, em seguida, prever ou prever essas tendências a partir daí
gerar nova saída (texto, imagem, vídeo, geração de áudio)
Os modelos ML são construídos a partir de uma ampla variedade de tipos de modelos estatísticos voltados para problemas específicos, cada um com um grande número de algoritmos estatísticos que podem ser usados em cada um. Alguns tipos comuns incluem:
Modelos de classificação são usados para classificar dados em categorias (rótulos), a fim de prever um valor discreto (qual categoria se aplica a novos dados).
Modelos de regressão são usados para encontrar correlações entre variáveis, a fim de prever valores contínuos (numéricos).
Os modelos de agrupamento são bons para agrupar dados em torno dos grupos naturais existentes, como segmentar clientes, fazer recomendações e processar imagens.
Há várias maneiras pelas quais o ML pode ser ensinado, incluindo:
Aprendizagem Supervisionada é o treinamento por meio de um conjunto de dados com respostas conhecidas. Essas respostas se tornam rótulos que o ML usa para identificar padrões e correlações nos dados.
Aprendizagem não supervisionada é o treinamento por meio de dados brutos e permite que a IA determine os recursos e tendências dentro dos dados. Isso é usado pelos sistemas de ML para fazer recomendações, associações de dados, isolamento de tendências ou segmentação de clientes.
O aprendizado semi-supervisionado está no meio, que usa um subconjunto de treinamento em um conjunto de dados rotulado e outro não rotulado para enriquecê-lo ainda mais.
A Aprendizagem de Reforço é um modelo que é recompensado por respostas corretas e oportunas (através de pontuações internas ou feedback humano). Isso é usado quando há um estado de início e fim conhecidos, onde o ML tem que determinar a melhor maneira de navegar pelos vários caminhos entre eles. Isso está sendo aproveitado em novos modelos de linguagem como o ChatGPT para melhorar a maneira como o mecanismo "fala".
Alguns dos componentes da construção de ML que são úteis para entender:
Recursos são características ou atributos dentro dos dados brutos que ajudam a definir a entrada (similares a colunas dentro de um banco de dados). Estes são então alimentados como entradas para o modelo ML e pesados uns contra os outros para identificar padrões e como eles se correlacionam entre si. A Engenharia de Recursos é o processo em que um cientista de dados pré-identificará essas variáveis dentro dos dados, como categorias ou intervalos numéricos para rastrear. A seleção de recursos pode ser necessária para selecionar um subconjunto de recursos na construção do modelo, que pode ser repetidamente testado para encontrar o melhor ajuste, além de ajudar a simplificar os modelos e encurtar os tempos de treinamento. Os recursos podem ser rastreados colaborativamente em Feature Stores, que são semelhantes às Metric Stores em pilhas de BI [ambas discutidas na Modern Data Stack]. O Aprendizado Não Supervisionado força o mecanismo ML a determinar os recursos importantes por conta própria.
A dimensionalidade é baseada no número de recursos fornecidos como entrada no modelo - ou melhor, representa as dimensões internas do modelo de como cada recurso se relaciona e afeta todos os outros recursos (como uma variável em uma linha de entrada afeta outra). Dados de alta dimensão referem-se a conjuntos de dados com um amplo conjunto de recursos (um alto número de variáveis de entrada por linha).
Observações são o número de conjuntos de recursos fornecidos como entrada durante a construção do modelo (se semelhante a linhas dentro de um banco de dados).
Vetores são recursos transformados em forma numérica e armazenados como uma matriz de entradas (uma por observação ou linha, ou uma frase de texto em PNL). Uma matriz de vetores é uma matriz bidimensional. [É por isso que as GPUs são tão úteis no treinamento de ML, pois são especializadas em matemática vetorizada.]
Os tensores representam as relações multidimensionais entre todos os vetores. É por isso que o Google e a NVIDIA usam o nome com frequência em produtos de GPU, pois são especializados em matemática vetorizada altamente dimensional.
Rótulos são respostas pré-definidas dadas a um conjunto de dados. Isso pode ser a identificação de categorias que se aplicam a esses dados (como cor, marca, modelo de um carro), resultados bem-sucedidos ou falhados (como se isso é fraude ou comportamento de risco ou não), ou a marcação e definição de objetos dentro de uma imagem ou vídeo (esta imagem contém um gato branco em uma mesa preta). Estes são então alimentados em métodos de Aprendizagem Supervisionada de treinamento de modelos de ML.
Parâmetros são o que o modelo ML cria como variáveis internas em um ponto de decisão. Esta é uma variável treinada que ajuda a definir a importância de um recurso individual dentro do mecanismo ML. (Isso pode ser pesos e vieses dentro de uma rede neural ou um coeficiente em uma regressão.) A contagem de parâmetros é uma maneira geral que os modelos ML usam para mostrar quanta complexidade eles escondem. (O GPT-3 da OpenAI tinha parâmetros 350M-175B em vários sabores, e acredita-se que o GPT-4 tenha até 1T.)
Hiper parâmetros são variáveis externas que o cientista de dados pode ajustar em algoritmos estatísticos individuais usados no modelo ML. Pense neles como os botões que podem ser ajustados e ajustados para ajustar o modelo estatístico interno (juntamente com o fato de que existem inúmeros modelos estatísticos que podem ser usados para qualquer algoritmo específico, que pode ser trocado).
Como em qualquer coisa relacionada a dados, é "lixo dentro - lixo para fora". Você deve começar com bons dados para ter um bom modelo de ML. A ciência de dados é, em última análise, a arte de criar um modelo de ML, que requer disputas de dados (a limpeza, filtragem, combinação e enriquecimento dos conjuntos de dados usados no treinamento), seleção dos modelos e algoritmos estatísticos apropriados a serem usados para o problema em questão, engenharia de recursos e ajuste dos hiperparâmetros. Essencialmente, a ciência de dados é sobre fazer as perguntas certas da maneira certa.
Os modelos de ML são treinados com dados e, em seguida, validados para garantir o "ajuste" (relevação estatística) à tarefa em questão, bem como podem ser ajustados e ajustados ao longo do processo de criação pelo cientista de dados (através dos dados de treinamento que estão sendo inseridos, os recursos selecionados ou hiperparâmetros no modelo estatístico). Uma vez em produção, é típico testá-lo ocasionalmente para garantir que permaneça relevante para os dados do mundo real (ajuste), pois tanto os modelos quanto os dados podem derivar (como comportamentos de mudança dos clientes). Os modelos podem ser treinados em mais e mais dados para se tornarem cada vez mais precisos em classificações, previsões e geração. Mais dados geralmente significam mais insights e precisão - no entanto, em algum momento o modelo pode sair dos trilhos e começar a tentar encontrar padrões em valores atípicos aleatórios que não são úteis. Isso é conhecido como "overfit", onde suas descobertas treinadas não são tão aplicáveis aos dados do mundo real, considerando o ruído ou a aleatoriedade mais do que deveria. Em seguida, deve ser treinado novamente em um conjunto mais atualizado de dados históricos
Redes Neurais
Uma forma de ML é conhecida como rede neural, que pega esse "cérebro de IA" (motor de computação) e divide sua arquitetura em milhares de peças individuais chamadas de "nós neurais". Isso é bem nomeado, pois funciona muito parecido com a forma como seu próprio cérebro é composto de células nervosas (tomada de decisões) e sinapses (interligando essas decisões e pesando-as umas contra as outras). A entrada pode ser dividida em centenas, milhares ou milhões de decisões ponderadas, o que pode desencadear outra camada de decisões.

Pesos são os parâmetros internos individuais de uma rede neural para pesar a importância de cada entrada (recurso) para a decisão em questão e como cada entrada se relaciona com as outras. Estes são os parâmetros definidos em uma rede neural durante o treinamento, que são então resumidos em cada nó para tomar uma decisão.
O viés é um parâmetro separado por camada de uma rede neural que permite aumentar ou diminuir a importância das decisões dentro dos nós dessa camada. Isso essencialmente equivale a colocar um polegar na escala de qualquer camada individual (ponto de decisão) dentro da rede neural, para tornar mais fácil ou mais difícil tomar essa decisão.
Uma função de ativação é o resultado final de um nó individual, que resume as entradas ponderadas mais o viés para tomar uma decisão e passar dados adiante.

Uma rede neural profunda tem um número de nós em qualquer número de camadas separadas (escondidas), permitindo que ela tome decisões complexas sobre dados altamente dimensionais.
Essa arquitetura é conhecida como DEEP LEARNING (DL), pois usa várias camadas separadas (cada uma com seu próprio conjunto de nós neurais) para poder navegar por decisões extremamente complexas sobre um grande número de variáveis. Os nós dentro de cada camada combinam todas as microdecisões em uma decisão final por camada, que depois passa para a próxima camada, e assim por diante. É uma cadeia dinâmica de mecanismos lógicos que interagem com outros mecanismos lógicos, iterando decisões juntos repetidamente, pesando os resultados e chegando a uma decisão final. Existem muitas formas de redes neurais, com base em como nós e camadas interagem, interconectam e fluem. Um tipo é uma Rede Neural Recursiva, que pode iterar decisões repetidamente à medida que pesa fatores da entrada, que são combinados para decidir como proceder.
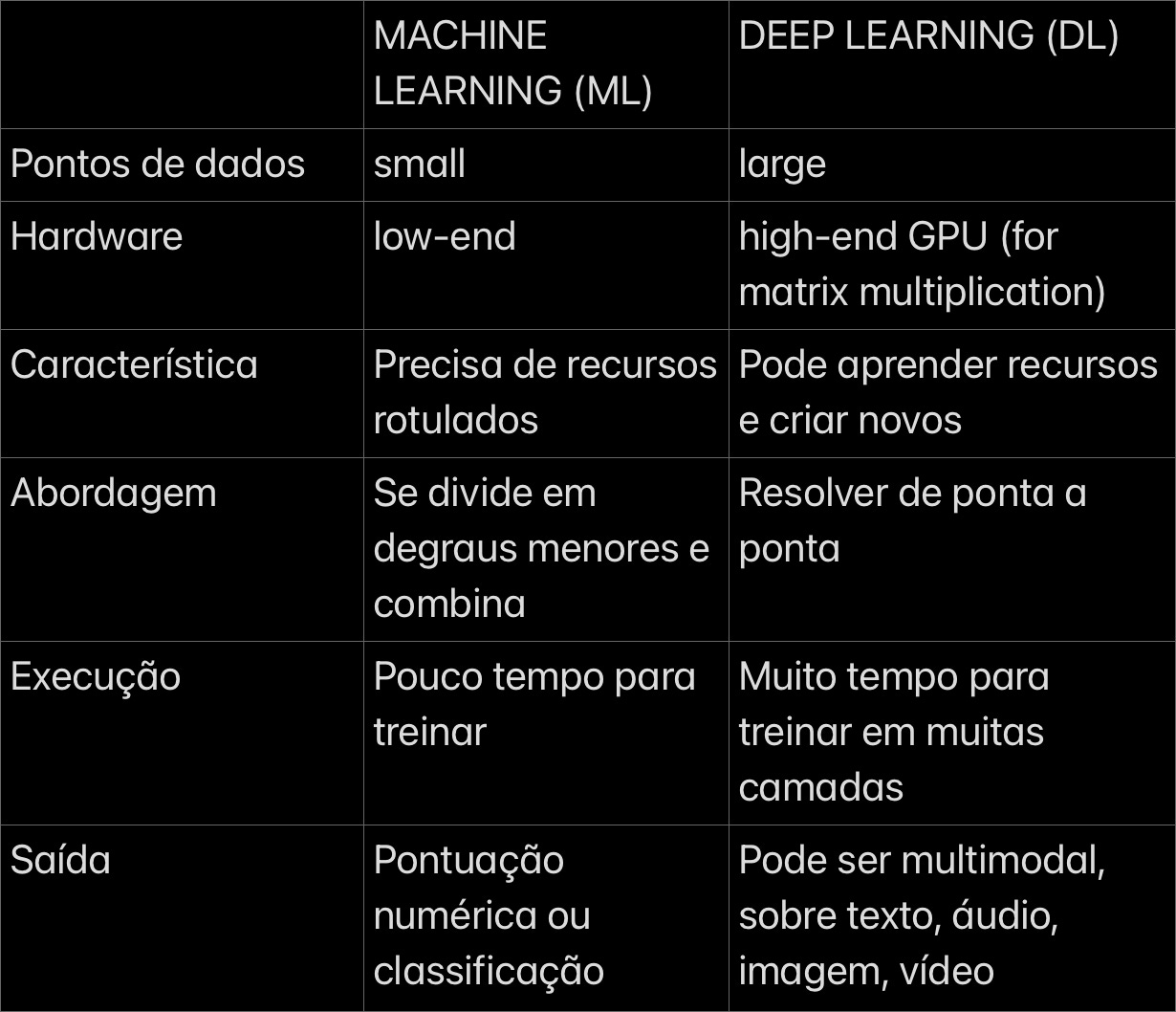
As Redes Neurais permitem o processamento de dados com alta dimensionalidade (as relações entre um maior número de recursos individuais, como colunas em um conjunto de dados ou termos de vocabulário), tornando-os adequados para lidar com a tomada de decisões em várias camadas sobre problemas complexos e para encontrar correlações entre conjuntos de dados díspares. Eles são ideais para previsão de séries temporais, detecção de fraudes, reconhecimento de padrões, detecção e classificação de objetos e compreensão e tradução de idiomas. Mas a capacidade de lidar com problemas mais complexos significa uma arquitetura e um processo de treinamento mais complicados. Algumas diferenças em relação ao ML incluem:
Uma chave para a rapidez com que as redes neurais têm iterado ultimamente está no uso de GPUs para treinamento e uso (inferência). Em última análise, os modelos de aprendizagem profunda são uma série de algoritmos matemáticos paralelos (em todos os nós em uma camada) sobre vetores (arrays de números) e matrizes (arrays de vetores). Outrora a província de jogos e gráficos avançados, as Unidades de Processamento Gráfico (GPUs) da NVIDIA e outras são ideais para processamento multiparalelo sobre matemática vetorizada (ou seja, multiplicação de matrizes). As GPUs são especialmente adequadas para redes neurais, e todos os hiperescaladores fornecem instâncias de GPU NVIDIA em seus mecanismos AI/ML (como IaaS ou PaaS), além de terem desenvolvido seus próprios chipsets altamente afiados (como Google TPU, AWS Inferentia/Trainium - o Azure está muito atrasado aqui, embora tenha sugerido a vinda chips especializados).
A escala da infraestrutura em nuvem expandiu muito a forma como essas IAs são construídas e como podem ser treinadas e, portanto, multiplicou a complexidade dos modelos e suas capacidades. O Azure tem uma parceria exclusiva com a OpenAI, criando um enorme conjunto de infraestrutura de supercomputadores no Azure que é dedicada ao treinamento e uso (inferência) de todos os modelos da OpenAI. [Mais sobre isso mais tarde.]
Outra inovação recente é o surgimento de bancos de dados vetoriais, que são bancos de dados especializados que armazenam e consultam vetores de alta dimensionalidade e suas relações com outros vetores (tensores). Esses bancos de dados são extremamente úteis em pesquisas de similaridade para mecanismos de pesquisa e recomendação e Visão Computacional, e estão acelerando a compreensão semântica na PNL. Esses bancos de dados podem ser consultados para encontrar imagens semelhantes sobre conteúdo e estilo, documentos sobre tópico e sentimento e produtos com recursos e classificações semelhantes. Os bancos de dados vetoriais podem essencialmente fornecer memória de longo prazo para IA.

Os bancos de dados vetoriais são um novo banco de dados especializado que surgiu para armazenar vetores e seus relacionamentos (tensores), de acordo com este gráfico da plataforma de banco de dados vetorial Pinecone.
Todos esses avanços em redes neurais profundas agora estão impulsionando grandes avanços na PNL e na IA Generativa.
PNL
PNL (processamento de linguagem natural) é um subconjunto de redes neurais focadas na compreensão da intenção e do contexto da linguagem. A PNL é uma área de IA que muitas vezes é voltada para o consumidor, como por meio de plataformas de assistente de voz como Apple Siri, Amazon Alexa e Google Assistant ("Ei, Google"). As PNL podem ser focadas para dentro (entendendo o significado da entrada) e/ou para fora (gerando saída textual). (Pense na geração de texto como prever como as palavras se unem, e você percebe como a PNL é semelhante ao reconhecimento de padrões e à previsão de séries temporais.) Novos avanços aqui estão capturando uma enorme quantidade de atenção, pois dá a um mecanismo de IA a capacidade de entender melhor nossas solicitações e responder conosco.
Os tokens são o primeiro passo na PNL para quebrar a linguagem textual ou o código em unidades básicas (palavras, subpalavras, caracteres, pontuação). Cada um deles recebe um ID numérico, que transforma as palavras em números. Esses tokens são então armazenados como um vetor (linha numérica de tokens) e se tornam a entrada (recursos) em uma PNL. Byte-Pair Encoding (BPE) é um método de tokenização que mescla os pares de palavras que ocorrem com mais frequência em um único token e é um método usado pelo OpenAI no GPT.
Uma incorporação é um processo de aprendizagem profunda de treinamento em vetores de palavras para construí-los em um modelo de alta dimensionalidade (tensor). Isso permite que uma PNL alinhe vetores em torno de significados semelhantes e entenda a relação semântica entre eles. Isso é usado para, em última análise, construir um vocabulário compreensível, permitindo que o modelo entenda e gere frases e parágrafos, e entenda palavras semelhantes com diferentes significados.
Os transformadores se tornaram um avanço importante que permite que um mecanismo de PNL extraia melhor o significado e o contexto da linguagem. Eles são projetados para processar rapidamente a entrada de texto e são ideais para tradução e resumo de idiomas. A chave para os transformadores é o conceito de auto-atenção, que permite que um transformador pese a importância de cada palavra em uma frase para as outras palavras durante a incorporação. Isso permite que o modelo se concentre nos fatores mais importantes do texto e, finalmente, melhore o contexto geral. (Um exemplo de contexto seria saber quando você diz "piscina" que quer dizer um verbo para agrupar algo, uma piscina ou um jogo de bilhar.) Os transformadores podem combinar palavras em grupos relevantes, dividi-las em sequências de significado e combiná-las em contexto para entender completamente a intenção. Esse mecanismo permite que ele pese a importância dos segmentos dentro de um texto geral e seja capaz de resumi-lo.
Transformadores são o "T" em motores de PNL como o BERT (código aberto do Google) e o GPT da OpenAI. Tanto os transformadores quanto a auto-atenção surgiram da Pesquisa do Google em 2017, que lançou o BERT (Bidirectional Encoder Representations from Transformers) como uma estrutura ML de código aberto para PNL em 2018.
Outro aspecto crítico é como os transformadores permitem o processamento de todas as entradas textuais de uma só vez, em vez de sequencialmente. Isso essencialmente permitiu que a PNL usasse melhor o processamento multiparalelo durante o treinamento, o que, combinado com melhorias no desempenho da nuvem, acelerou muito a forma como os modelos de PNL podem ser iterados e aprimorados.
IA Generativa
A IA gerativa é um termo genérico para essa nova geração de IA que pode ser usada para gerar conteúdo construído em seu "conhecimento" treinado, em vez de um aperfeiçoado em torno de casos típicos de uso de ML de previsão e classificação de dados. (Embora, na verdade, esteja prevendo - prevendo sua resposta a partir do conjunto de conhecimento que construiu.) O que as interfaces de prompt de bate-papo interativo estão permitindo é melhor aprimorar suas solicitações, para que possa haver um processo de refinamento. O que vemos explodindo nas notícias ultimamente são redes neurais profundas avançadas que são:
IAs Generativas: Motores de IA especializados na geração de conteúdo criativo (imagem, vídeos, áudio, texto ou multimodal). Mecanismos de texto para imagem como DALL-E, Midjourney e Stable Diffusion da OpenAI (código aberto da Stability.ai) surgiram no ano passado para permitir que você crie imagens a partir de prompts baseados em texto. Vídeo, áudio e outros formatos estão surgindo.
Grandes Modelos de Linguagem (LLMs): Uma forma de IA Generativa que é um enorme mecanismo de PNL (processamento de linguagem natural) capaz de entender e responder à linguagem textual. Esses modelos são extremamente úteis para classificação, resumo, tradução e geração de texto (diálogo) - que se combinam em um assistente virtual útil para entender, resumir e gerar texto. Mecanismos avançados de LLM como ChatGPT da OpenAI, Google Bard, LLaMA (código aberto do Facebook) e Dolly (código aberto da Databricks) surgiram nos últimos meses.
As IAs generativas treinam em um enorme corpo de conteúdo anterior (como imagens existentes) para derivar características e contexto do objeto. Os LLMs treinam em um enorme corpo de texto (como páginas da web públicas) para construir um conhecimento geral de linguagem, e ambos compreendê-lo e gerá-lo. Os modelos LLM são adequados para:
classificação de texto: atribua rótulos/categorias ao texto
resumo de texto: extraia as informações mais relevantes do texto, recapitula pontos importantes
tradução de texto: converta de um idioma para outro
geração de texto: crie texto novo e original
Os transformadores foram fundamentais para desbloquear todos os novos LLMs que desde então emergiram do OpenAI e outros, e por que mais emergem a cada semana. E esses avanços não são apenas para texto (linguagem e código) - os transformadores são multimodais e são aplicados a outros formatos, tornando-os também úteis no avanço da Visão Computacional na extração de significado de dados não estruturados e na geração de imagens e vídeos.
A OpenAI tornou-se um nome familiar em seus avanços contínuos em LLMs nos últimos anos e tem estado ocupada aperrá-los para diferentes fins. Um avanço foi em seu mecanismo Codex, uma especialidade LLM que pode entender e gerar código de aplicativo (linguagens de programação). Outro estava no ChatGPT, onde o OpenAI treinou seu LLM principal (GPT-3) usando aprendizado de reforço (de treinadores humanos) para treiná-lo para entender e responder por meio de uma interface de bate-papo iterativa (fazendo o chatbot mais avançado que o mundo já viu). Seu novo GPT-4 é prometido ser multimodal e em breve aceitará imagens como entrada, bem como texto.
Os transformadores provaram ser um grande avanço na IA gerativa - tanto que um mecanismo Transformer agora foi incorporado diretamente na mais recente linha de GPUs "Hopper" da NVIDIA (H100), com seu anúncio em 22 de março afirmando:
"Agora a escolha do modelo padrão para processamento de linguagem natural, o Transformer é um dos modelos de aprendizagem profunda mais importantes já inventados."
E não são apenas os Transformadores que estão desbloqueando o potencial da IA Gerativa. Generative Adversarial Networks (GANs, um modelo de 2 lados para gerar conteúdo e avaliá-lo contra a realidade) e Diffusion (adição/remoção de ruído para isolar melhor objetos em imagens, o que melhora a geração e fusão de objetos) são 2 outros modelos de redes neurais que estão ajudando a avançar a IA generativa para criar conteúdo realista em imagens e vídeos
Embora haja uma clara mentalidade de "corrida do ouro" com IA/ML, não é injustificada, pois houve uma enorme mudança de paradigma com IA Gerativa e LLMs.
A fabricante de chips Nvidia (NVDA), um dos maiores beneficiários das tecnologias de IA, subiu na quinta-feira à medida que seu balanço e receitas superaram as expectativas. No entanto, o que levou a NVDA a subir mais de 25% não foram seus resultados trimestrais, mas sim suas perspectivas. A administração da NVDA surpreendeu os investidores ao prever US$ 11 bilhões em receita para o segundo trimestre, bem acima da previsão anterior que foi de US$ 7,18 bilhões. Um aumento tão acentuado em um curto período é quase sem precedentes. Os analistas de Wall Street aumentaram rapidamente suas metas de preço para a NVDA. Muitas outras ações relacionadas à IA estão seguindo a liderança da NVDA no ano.
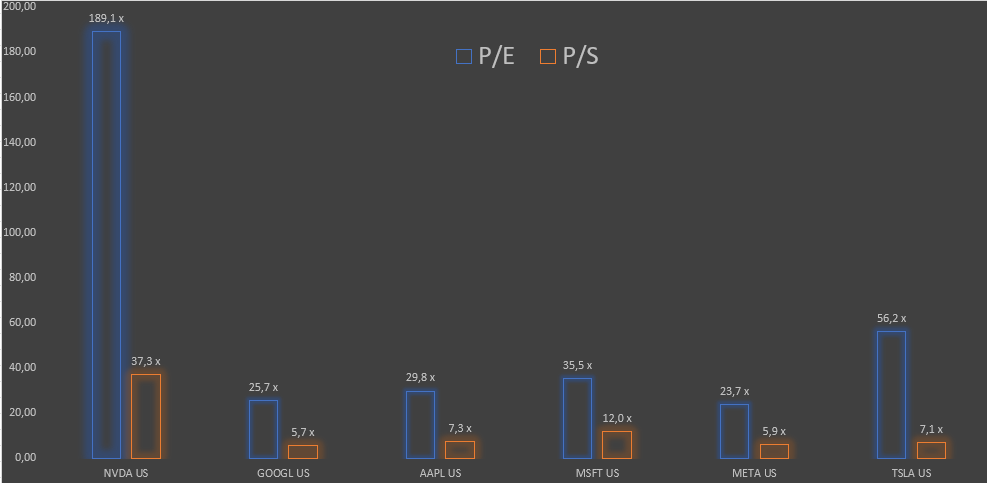
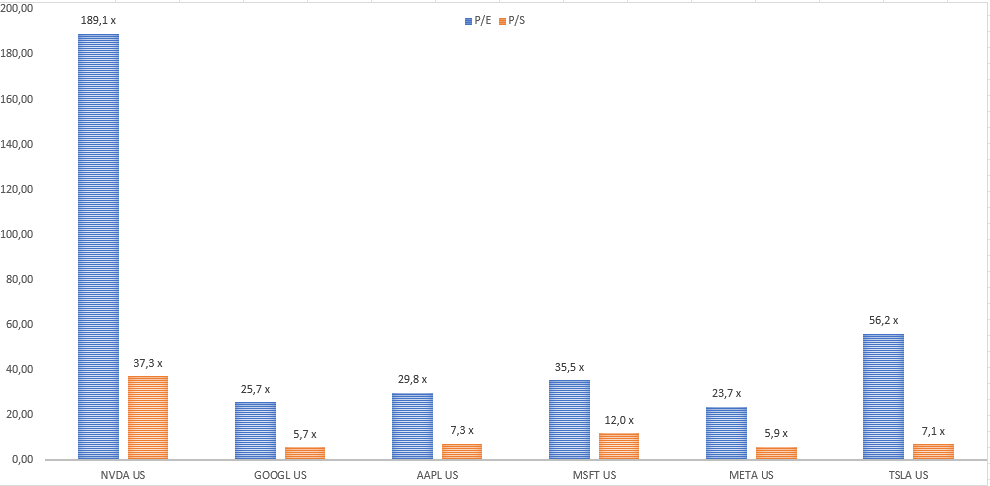
Com o aumento do preço de quinta-feira, a NVDA ganhou mais de US$ 220 bilhões em capitalização de mercado. Para colocar isso em contexto, um concorrente de IA deles, a AMD, tem uma capitalização de mercado de US$ 174 bilhões. Além disso, 473 ações da S&P 500 têm um valor de mercado abaixo de US$ 220 bilhões. A NVDA se beneficiará muito da IA. A questão, no entanto, para os investidores é se o valuation da NVDA e de algumas outras empresas de IA estão corretos. Ou seja, em sua atual relação price/sales de 39x, a NVDA terá que possuir todo o espaço do mercado de chips de GPU em dez anos, mantendo o preço das ações neste patamar ate la, ainda sim o price/sales será de 13x . O P/E e o P/S da NVDA superam outras big techs como Apple, Microsoft, Google e Meta.
Aqui vale uma ressalva, estamos extrapolando o modelo para buscar um resultado ultra otimista, então estamos colocando um crescimento composto trimestral de 15,3% o que é muita grosseria. Na questão da margem do fluxo de caixa, mantê-lo acima de 30% constante é insano, se o objeto é ser otimista, então aqui vamos nos!!!
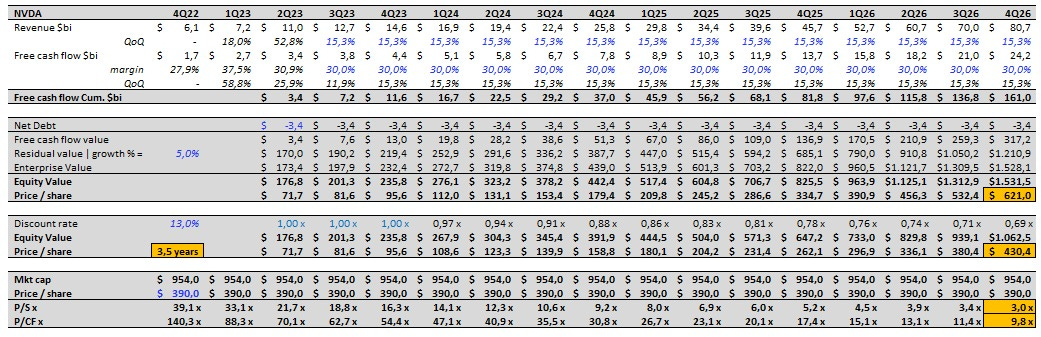
Fazendo uma modelagem de fluxo de caixa descontado ( DCF ) de NVDA usando as premissas abaixo:
- crescimento tri a tri até 4Q26 de 15,3%
- FCF margem 30%
- custo de capital de 13%
- crescimento na perpetuidade de 5%
- fair value da ação em 12 meses US$430 (consenso dos analistas)
Seriam necessários 3,5 anos para gerar o FCFE necessário para suportar o atual valuation de aquisição hoje de $390 / ação.
Vale destacar que a empresa esta crescendo trimestre a trimestre 15,3% e mantendo margem FCFE de 30%! Em 2026 empresa estaria faturando $265 bi (6x o último guidance anualizado $44 bi ou $11 bi para o 2Q23)! A Apple fatura $385 bi, ou seja, a NVDIA estaria faturando 70% da Apple em apenas 4 anos!
Se a empresa atingir $265 bi de faturamento em 2026 com esses níveis de rentabilidade, a empresa estaria sendo negociada a 3,0x Price/Sales dado o market cap de hoje e o faturamento de 2026. Hoje a empresa esta sendo negociada a 22x com base na receita anualizada do 2Q23 (guidance de $11 bi).
Conclusão
É inegável que estamos vivendo a história diante dos nossos olhos e que realmente a inteligência artificial ira mudar nossas vidas para sempre. Muitas empresas irão surgir, não precisamos ir muito para trás no tempo, até janeiro deste ano ninguém sabia o que era o ChatGPT, hoje sem duvida, a OpenAI é uma das empresas que mais crescem no mundo, com seu valor de mercado de mais 29 bilhões de dólares em pouco mais de 6 meses e já ameaçam um dos gigantes de tecnologia como o Google.
Nesse meio tempo muitas empresas irão fechar suas portas, pois a tecnologia irá engoli-las, com isso minha provocação:
Será que pagar valuations astronômicos em empresas num horizonte temporal de mais de 3 anos é um bom risco retorno, num cenário onde a a dinâmica tecnológica ira mudar radicalmente em ciclos de 2 anos?
É notório que o caso da NVDA é uma ‘‘corrida do ouro’’, o mercado sem muitas opções concentrou suas energias nos cases mais óbvios e sem duvida o price action da NVDA reflete isso. Vimos que nos modelos ultra otimistas que projetamos acima, com premissas ultra exageradas, não conseguiram chegar nem perto de uma explicação razoável para o preço das ações da NVDA hoje. Tudo leva a crer que nesse cenário de excesso de concentração + falta de opção está nos levando para algo digno de um bolha, porem ainda no começo.
Sem duvida, o modelo atual de fundos passivos e concentração nas big techs está comprimindo todo o prêmio de risco do mercado. Então no curto prazo, todos que tentaram ‘‘shortear’’ o SPX e o NDX não tiveram sucesso e acabaram sendo estopados.
Abaixo a contribuição (year-to-date) no índice SPX até o presente momento.
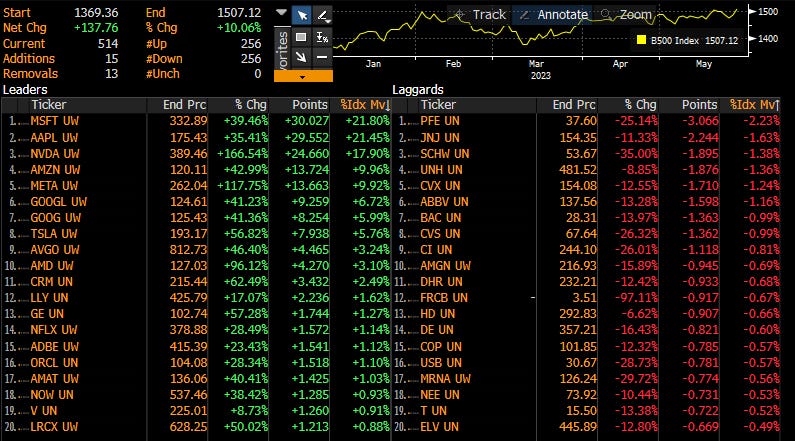
Vemos que MSFT, AAPL e NVDA representaram mais de 60% do movimento do índice SPX esse ano. Vale ressaltar que NVDA tem 4% do índice. Essas 3 ações com a ajuda dos fundos passivos que agem como amplificadores dos movimentos, enterraram o BEAR MARKET e deixaram de lado todo o resto das narrativas. Sendo assim, tirando NVDA, que parece estar com mais emoção do que razão, as outras ações estão com valuations razoáveis e afastando a tese de bolha.
Isso explica algumas distorções que estamos presenciando, como:
1- O RSP ( SPY equal weight ) com o SPY
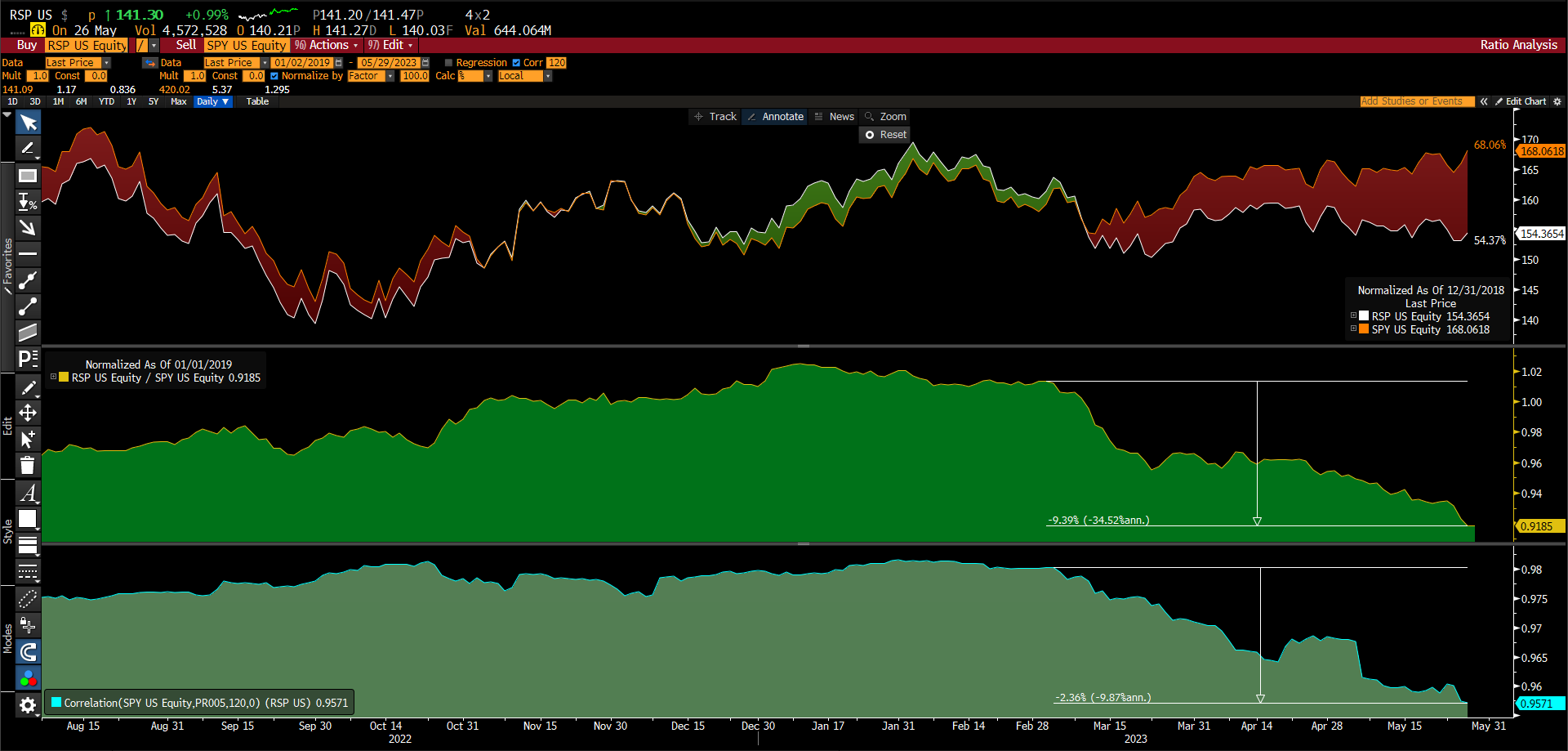
2- índice NDX descolar do GOVZ ( ETF long maturity 25+ long em tresuries )
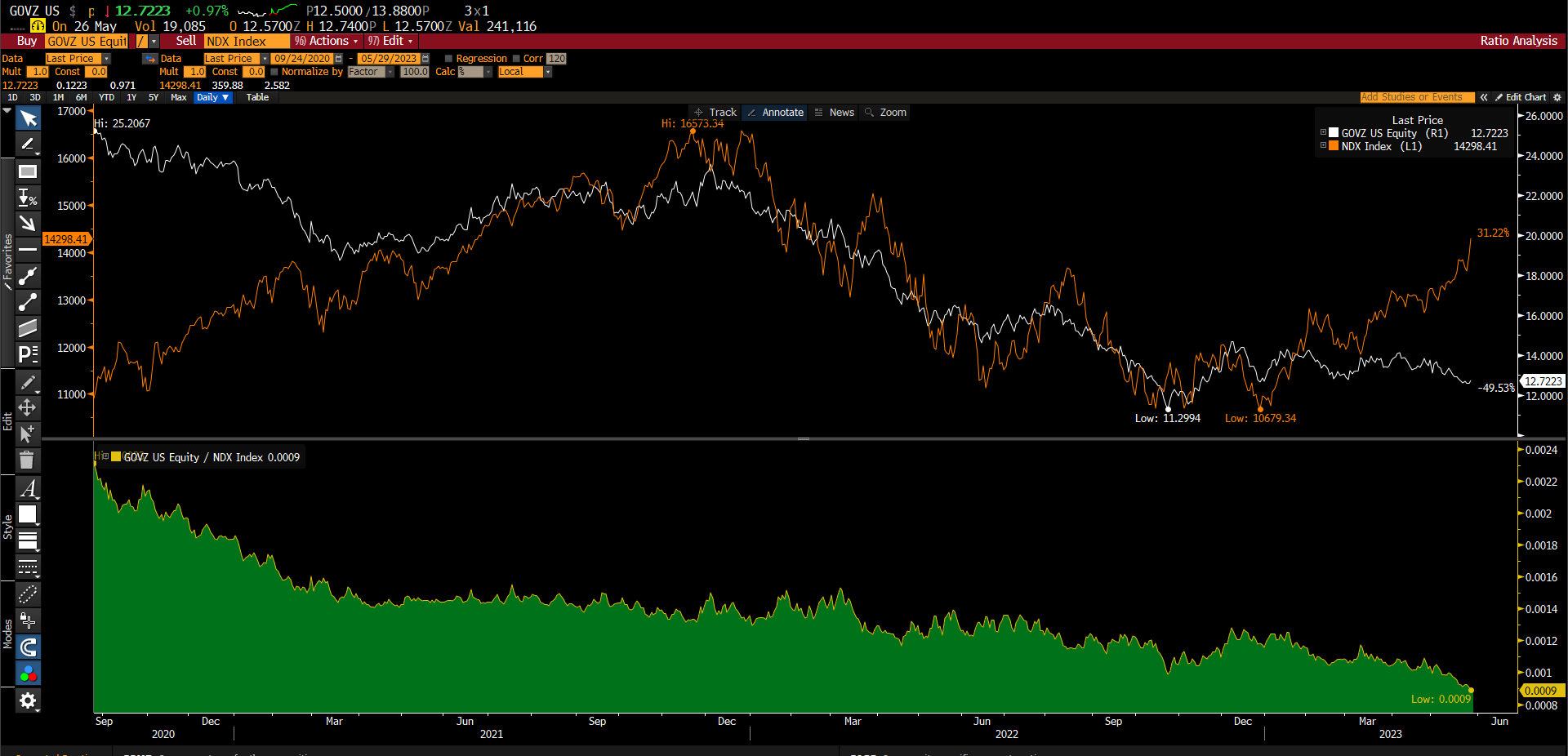
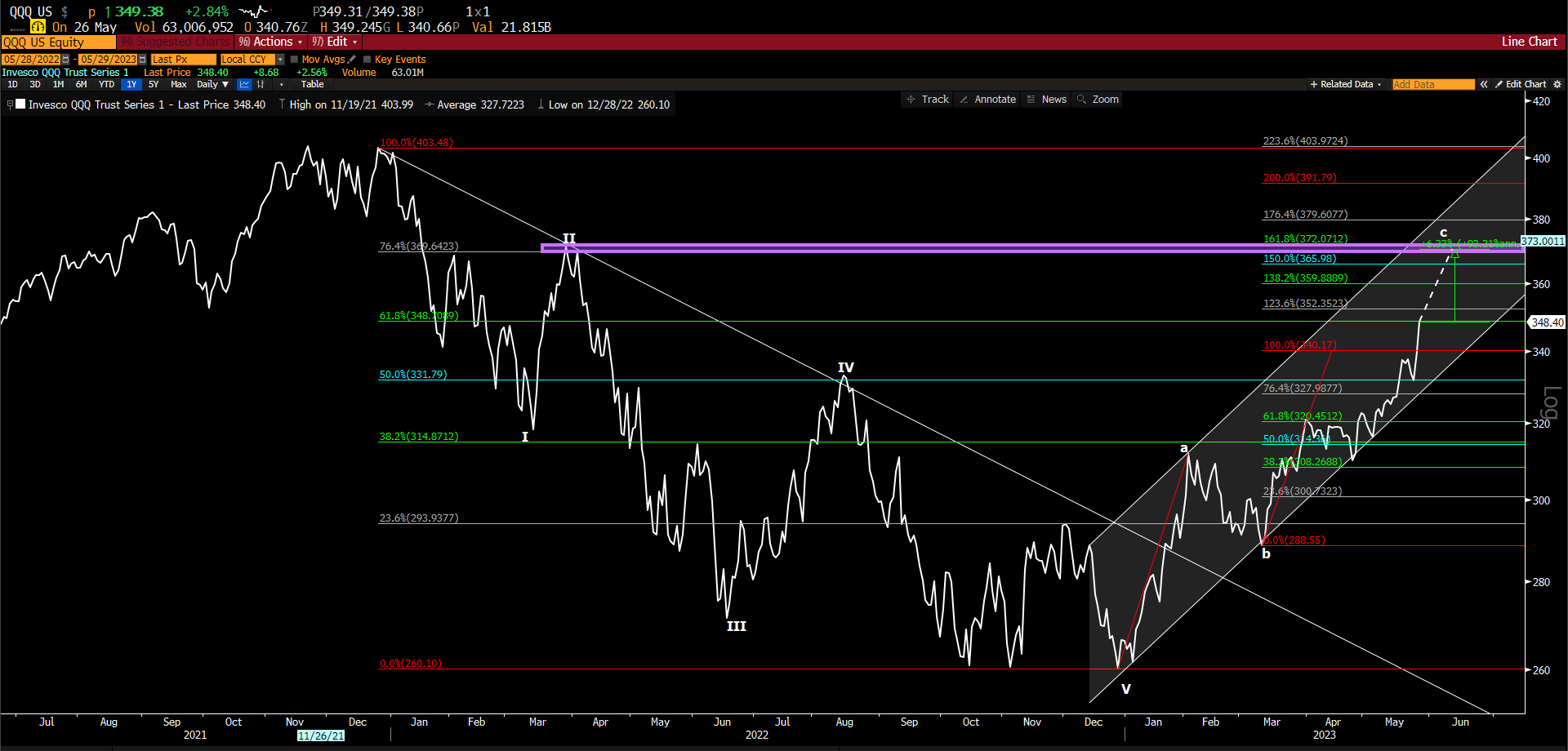
O QQQ ( ETF do índice Nasdaq ) está num ponto importante que é a retração de 61,8% de Fibonacci do movimento de queda que começou em 2022, o rompimento dessa região pode levar o QQQ para região de 370-372 que é uma área de confluência de 76,4% de retração do movimento de queda de 2022, junto com a projeção de 161,8% do ABC do fundo de outubro de 2022.